In the landscape of modern software architecture, the shift from monolithic systems to microservices has been revolutionary. Yet, with this transition comes the complexity of monitoring numerous smaller, interdependent services.
Effective microservices monitoring ensures optimal performance, swift problem resolution, and overall system robustness, which is pivotal for today's digital businesses. Simply put, it's like zooming in closely to see an entire picture and every tiny dot that makes it up. In a microservice architecture, each microservice can be considered a small, independent component of a larger system. Each microservice requires monitoring for specific characteristics such as response time, error rates, and resource usage for overall system health.
This article explores microservices monitoring strategies and best practices for enhanced efficiency and effectiveness.
Summary of key microservices monitoring concepts
Traditional vs. microservices monitoring
Traditional application monitoring typically focuses on overall server health, database performance, and application uptime, examining the system as one unified entity. For instance, it might track how long a webpage takes to load or if a database is accessible. In contrast, microservices monitoring delves into each independent service of a similar website: the product catalog, user authentication, payment processing, etc.
Monitoring practices have had to evolve significantly in transitioning from traditional to microservices architecture. Every microservice potentially runs in different environments and requires individual health checks. This shift demands tracking the performance of each service and understanding how they communicate and affect each other. While traditional monitoring might tell you that the website is down, microservices monitoring pinpoints that the issue originates specifically from the payment service failing to communicate with the user authentication service. It requires more sophisticated tools like distributed tracing.
{{banner-32="/design/banners"}}
An overview of the monitoring process
Monitoring collects data on performance metrics that serve as benchmarks to ensure the services operate within desired parameters. It’s vital to monitor each service’s performance meticulously. The process is as follows
- For each microservice, identify key performance indicators (KPIs) such as response time, error rate, and throughput.
- Track the performance over a period to establish a baseline.
- Based on the baseline and SLOs, set thresholds for performance metrics.
Metrics should align with the business goals and user experience objectives. For instance, observe the average response time of a microservice over a week. If the average response time of a service is 100ms, you might set a warning alert at 120ms and a critical alert at 150ms. Tools like Catchpoint for metric collection and visualization can be set up. For instance, it can scrape metrics from each microservice and store them for analysis and alerting.
Collect data consistently across all services to analyze patterns and trends in the metrics. Look for deviations or anomalies that might indicate underlying issues. Use dashboards that provide a unified view of all microservices and their performance metrics.
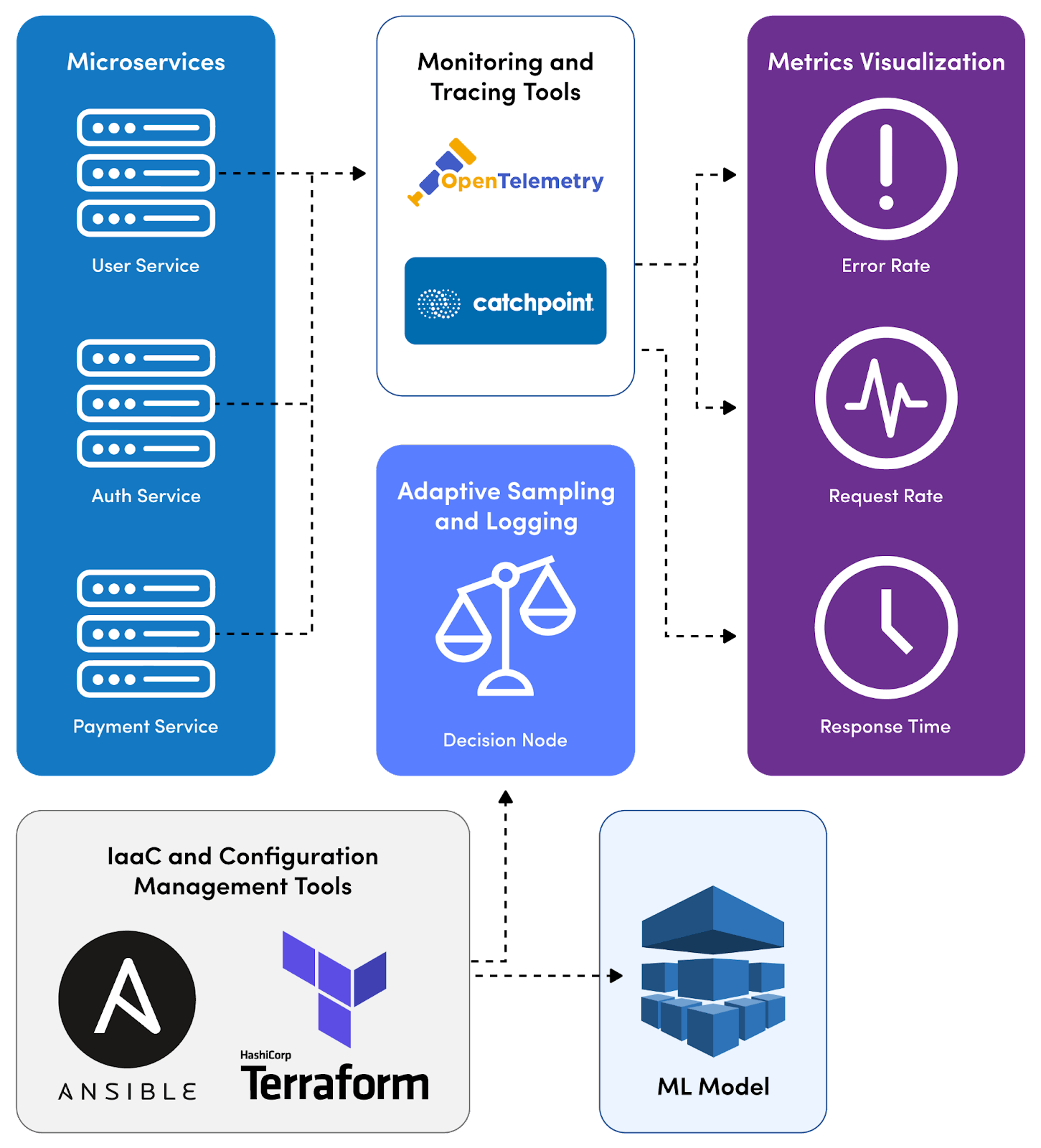
The above representation depicts a microservices monitoring ecosystem that works as follows.
- Microservices are integrated with monitoring tools OpenTelemetry and Catchpoint for data collection and analysis.
- Metrics and traces from these services are channeled through an adaptive sampling and logging mechanism controlled by decision-making processes.
- Configuration management tools Ansible and Terraform are utilized to manage the monitoring infrastructure.
- A machine learning (ML) model is incorporated for advanced data analysis.
The outcome of these processes is visualized, displaying key performance metrics like error rate, request rate, and response time to monitor the health and efficiency of the microservices architecture.
{{banner-31="/design/banners"}}
The role of distributed tracing in microservices monitoring
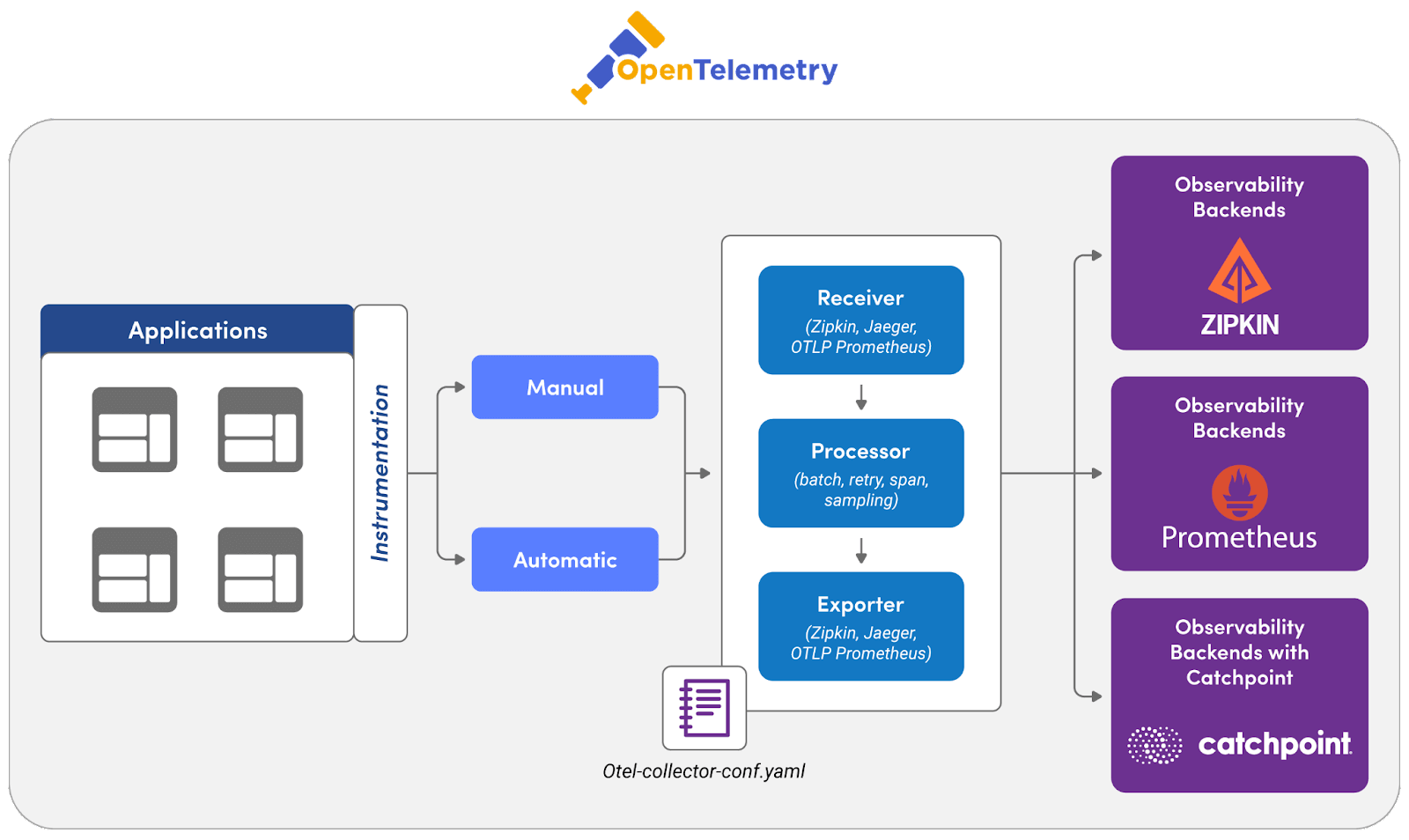
Distributed tracing provides clear visibility into how requests traverse various services. Tracing tools differ in features, ease of integration, and scalability. Popular options include OpenTelemetry and Catchpoint.
Start by choosing a tracing system compatible with your technology stack. Once a tool is chosen, the next step is to instrument your application. Libraries like OpenTelemetry provide APIs and SDKs for various languages, allowing you to annotate and track requests as they move through your services. Ensure that each request carries a unique identifier passed across service boundaries. This identifier, often called a "trace ID," helps in stitching together the entire path of the request across various services. Tracing tools typically aggregate data in a backend system, where it can be analyzed. The choice of the backend (e.g., Elasticsearch, Apache Cassandra, Clickhouse, Hydrolix) depends on factors like scalability, query capability, and existing infrastructure.
Consider an online shopping application composed of multiple microservices: User Authentication, Product Catalog, Shopping Cart, and Checkout. By implementing distributed tracing, each user request receives a unique trace ID, from login to checkout. As the request moves through each service, spans (individual units of work, like querying a database or calling an external API) are recorded with this ID. If a user experiences a delay during checkout, engineers can trace the exact request path to identify the service causing the lag and focus their debugging efforts.
Example code
The code sample below adds a Google Cloud Trace. Similarly, you can add a trace in Catchpoint too.
Open the **pom.xml** file in the Java Application and add below dependency:
Open you Java code and add below snippet to Create spans
Start your application and hit the endpoint, you will see output like below in Cloud Trace.

Best practices in microservices monitoring
Next let’s look at the top six strategies for microservices monitoring success.
{{banner-30="/design/banners"}}
#1 Emphasize granularity in individual service monitoring
Implement monitoring at the level of individual services and transactions using tools like Catchpoint, which offer transaction tracing capabilities to track the journey of a request across microservices.
Consider a user-facing service experiencing increased latency. By examining distributed tracing reports and specific metrics like average response time (calculated as total time taken / total number of requests) and error rate, engineers can quickly discover whether the issue originates from the service itself or downstream dependencies. A sudden spike in average response time and an increased error rate can indicate service-specific bottlenecks. Metrics to measure include:
- Request rate: Number of requests per unit time, indicating the load.
- Error rate: The percentage of all requests that result in an error (Error Rate = Total Errors / Total Requests * 100).
- Response time: Time taken to return a response, an indicator of service speed.
For instance, if a payment processing service shows a consistently high error rate, it might suggest issues like API errors or service timeouts, necessitating a deeper investigation into API health, database response times, or other downstream services/APIs.
#2 Balance detail with efficiency
Implement selective monitoring and intelligent data collection to maintain system efficiency without compromising the quality of insights. Implementing adaptive sampling for trace data can help. In periods of normal operation, sample a smaller percentage of traffic for detailed tracing (e.g., 1-5%). Increase this rate during anomalies or high-error states to capture more data for analysis.
Consider a user authentication service that logs only essential information (e.g., INFO level) and collects aggregated performance metrics in normal conditions. However, if an anomaly like a sudden increase in response time is detected, the service automatically switches to a more detailed logging level (e.g., DEBUG). The monitoring team can diagnose the issue without sifting through excessive logs during normal operations.
#3 Dynamically adjust monitoring based on conditions
Use infrastructure as a code (IaaC) and configuration management tools (e.g., Terraform, Ansible) to script and automate the conditions under which monitoring levels should change.
For e.g. in an e-commerce application, the checkout service is monitored for standard metrics like throughput and error rates. A machine learning model running on the monitoring data detects an anomaly i.e. a sudden drop in throughput, and triggers an alert. This alert then initiates a script that increases the granularity of logging and tracing for the checkout service, enabling rapid diagnosis and issue resolution.
#4 Prioritize anomaly detection
Anomaly detection in microservices monitoring is crucial for maintaining system reliability and user satisfaction. By detecting irregularities in system behavior or performance early, you can proactively address issues before they escalate into significant problems, affecting user experience or system stability.
Start by mapping out the critical user journeys within your application, such as sign-up, login, checkout, etc. Understanding these paths helps in prioritizing which microservices need closer monitoring. Implement a monitoring solution that captures key performance indicators (KPIs) across all services. This goes beyond error rates and response times to include more granular metrics like transaction volume, user concurrency, etc.
Use streaming data processing frameworks like Apache Kafka and Apache Flink for real-time data analysis. By analyzing data streams, you can correlate anomalies across different services in real time, quickly understanding their impact on overall system health.
Integrate diagnostic tools within each microservice to effectively drill down into anomaly origins. This involves setting up detailed logging and tracing systems that can be activated on-demand or in response to specific anomaly triggers.
Example
Consider an e-commerce platform with microservices for user authentication, product search, inventory management, and payment processing. An anomaly detection system might spot an unusual spike in error rates in the payment processing service. The system automatically initiates a deep trace, collecting extensive logs and performance metrics at a granular level. These logs include detailed information about database queries, external API calls, and internal processing steps. The detection also triggers alerts, so engineers can promptly analyze the data and pinpoint the exact step where the issue occurs, whether it's a slow database response or a failed external API interaction.
#5 Use performance monitoring for capacity planning and infrastructure scaling
Start by analyzing current and historical performance data of your microservices to identify usage patterns and growth trends. Look at the long-term trends in metrics like CPU usage, memory demands, and network I/O. Identify peak usage times and normal operating baselines.
You can then use predictive analysis to forecast future capacity requirements. Tools like Google Cloud's AI Platform can assist in predicting future traffic based on historical data. Predictions can further be used to configure auto scaling policies in cloud environments. For example, initiating a new service instance when CPU utilization remains over 70% for a certain period. The targeted approach to scaling is more efficient than scaling the entire application stack.
{{banner-29="/design/banners"}}
#6 Integrate a service mesh for enhanced microservice management and observability
Incorporating a service mesh into a microservices architecture can revolutionize how traffic management and observability are handled. This integration not only improves visibility into the performance and health of each microservice but also offers advanced control over inter-service communications.
Start by selecting a suitable service mesh platform, like Istio, that integrates easily with existing monitoring solutions. Deploy the service mesh across your microservices. This typically involves installing a sidecar proxy (like Envoy) alongside each microservice, which handles all network communications.
Configure the service mesh to collect and export metrics relevant to each service’s performance and health. Ensure these metrics are fed into your monitoring tools. For example, configure Catchpoint to scrape metrics from the Envoy proxies and visualize this data using dashboards. Once you are set up, you can:
- Access granular data about service interactions.
- Experiment and optimize these interactions with service mesh traffic control features
- Pinpoint errors and their sources quickly via the service mesh’s logging and tracing capabilities.
For instance, you can use Istio’s telemetry features to understand the latency introduced by specific service paths or to trace request flows through the network. Techniques like canary deployments or A/B testing can be managed directly through the service mesh, monitoring how changes impact your key metrics.
Microservices monitoring for security
In the microservices paradigm, where services are loosely coupled yet function cohesively, the necessity of securing individual components and interactions become more essential.
Begin by auditing all exposed endpoints of each microservice. Document the nature (REST, GraphQL, etc.), purpose, and existing security measures of these endpoints. You can then implement Web Application Firewalls (WAFs) and network firewalls customized to each endpoint's specific needs. This should be followed by setting up custom security rules based on the endpoint's usage patterns and vulnerability assessments. Regularly update and refine firewall rules and network policies based on evolving threat landscapes.
Implement continuous security monitoring by integrating Intrusion Detection Systems (IDS) and Intrusion Prevention Systems (IPS) that are customized for microservices architecture. Use network segmentation, TLS encryption for data in transit, and robust authentication & authorization mechanisms for each service interaction.
Metrics to monitor may include:
- Count and type of security incidents detected within inter-microservice communications (e.g., unauthorized access attempts, data leaks).
- Latency and throughput metrics, indicating the impact of security measures on inter-service communication.
- Rate of successful vs failed intrusion attempts.
- Frequency and nature of policy updates and rule changes in response to detected threats and vulnerabilities.
- Incident response time for detected threats.
- Percentage of traffic flagged as suspicious or malicious.
- Compliance rate with predefined security standards and protocols.
Schlussfolgerung
In the dynamics of microservices architecture, monitoring forms the backbone of operational excellence, ensuring services run optimally and issues are quickly addressed. Key metrics such as request rate, error rate, and response time are vital for identifying issues like bottlenecks or service timeouts. Tools like Catchpoint offer deep insights into request pathways across services. Ultimately, microservices monitoring strategies and best practices reflect an overarching goal: to improve the robustness, efficiency, and security of digital businesses in an increasingly service-oriented world.
{{banner-28="/design/banners"}}

