Internet Outages Timeline
Dive into high-profile Internet disruptions. Discover their impact, root causes, and essential lessons to ensure the resilience of your Internet Stack.
January

TikTok

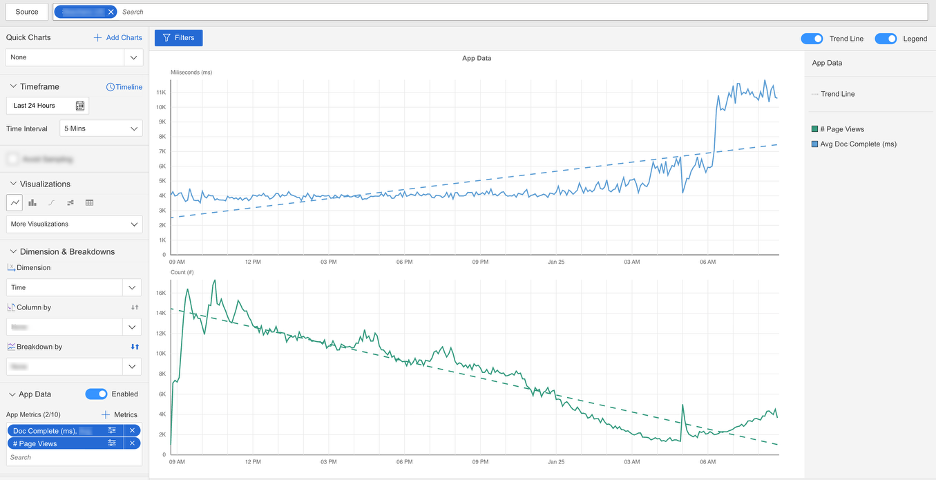
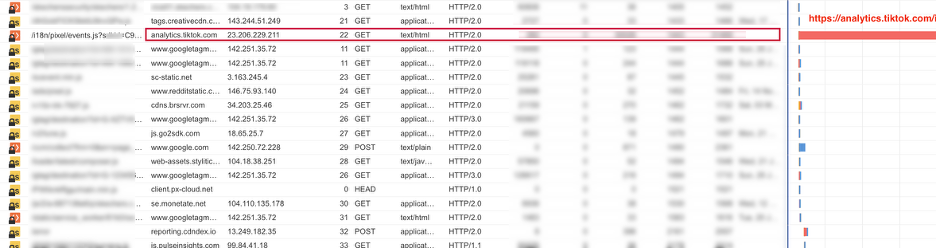
What Happened?
Catchpoint test data and browser timing showed that requests to TikTok’s analytics service were delayed during the connection (TCP connect) phase, with connection times reaching 20–30 seconds in some cases. DNS resolution, SSL negotiation, server processing, and page rendering times were normal, indicating the delay occurred before a successful network connection was established.
Because the TikTok scripts were included in the critical page load path, browsers waited for these third-party connections before completing the page load. As a result, pages appeared slow or unresponsive to users, even though the website’s own application, backend services, and CDN were operating normally and availability remained high.
Catchpoint RUM data showed the real user impact clearly:
• 37% reduction in page views
• 24% increase in bounce rate
• Degradation across Core Web Vitals, driven entirely by third-party behavior
Takeaways
• Third-party scripts can slow down a site even when everything else is healthy.
• Synthetic and RUM monitoring help separate third-party problems from application or infrastructure issues.
• Monitoring the full Internet stack makes it clear where time is being lost, such as DNS, connection setup, or response delays.
• Internet resilience depends on limiting critical page load dependencies on external services and isolating analytics or marketing scripts when possible.

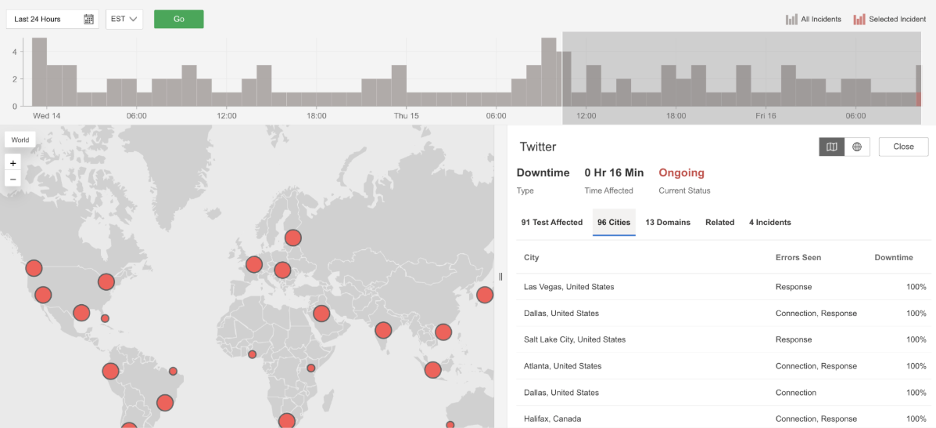
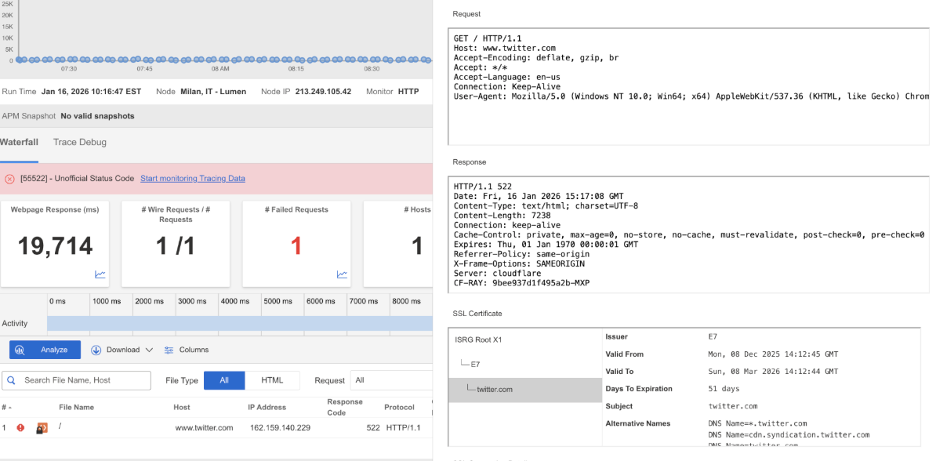
What Happened?
At 10:11 AM EDT, Twitter experienced a widespread service disruption affecting users across multiple regions. Many users were unable to load the platform or establish a connection at all. Requests failed with HTTP 522 (Connection Timed Out) errors, which means the network could not successfully connect to Twitter’s servers within the expected time. This pointed to a global connectivity or server-side issue rather than a problem limited to a single country or network.
Takeaways
Because connections to Twitter’s servers were timing out, users were unable to access timelines, post content, or refresh the service during the outage window. Large social platforms depend on reliable connectivity between users, networks, and backend infrastructure, and failures anywhere along that path can quickly affect millions of people. Independent, external monitoring across regions helps confirm when outages are truly global and provides visibility into whether issues stem from network routing, connectivity, or the application layer itself.
Cequence
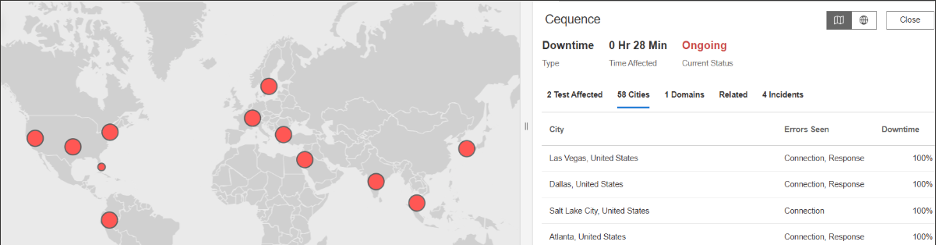
What Happened?
At approximately 10:17 PM EST, Cequence experienced a service disruption affecting users in multiple regions, including the United States, Poland, and France. Requests to Cequence services began failing with HTTP 504 (Gateway Timeout) errors. This means the service did not receive a response from an upstream system in time, causing requests to fail and users to experience unavailable or unresponsive services during the outage window.
Takeaways
Because Cequence relies on upstream systems to respond quickly, delays or failures in those dependencies can directly impact user access. Timeout-related outages highlight how issues in backend infrastructure or network paths can cascade into visible service failures. External, Internet Performance Monitoring (IPM) across regions helps confirm whether problems are localized or widespread and provides independent visibility into availability when internal systems are degraded.
Microsoft Office
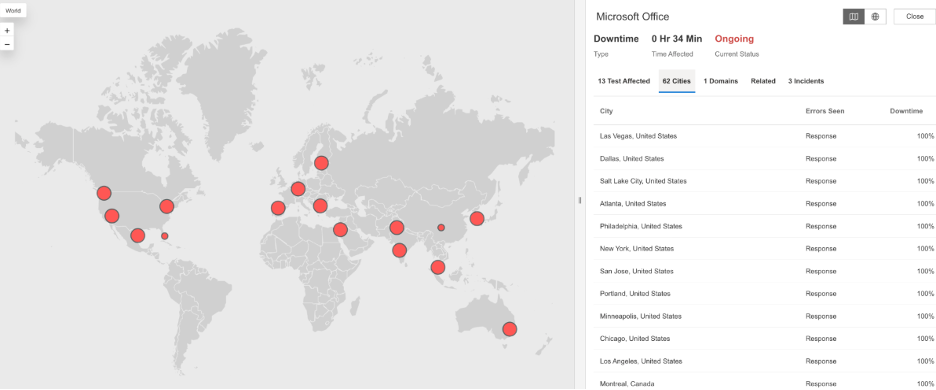
What Happened?
At 3:04 PM EST, Microsoft Office experienced a service disruption affecting users across multiple regions. Users attempting to access Office services encountered HTTP 503 (Service Unavailable) errors, which means the service was temporarily unable to handle requests. This indicated that Microsoft Office servers were either overloaded or unavailable during the outage window, preventing users from accessing Office applications and services.
Takeaways
Because Microsoft Office services were unavailable, users were unable to access productivity tools they rely on for daily work. Even short periods of unavailability can have outsized effects when widely used cloud applications are involved. Monitoring availability from multiple global locations helps confirm whether issues are regional or widespread, while visibility across the application and delivery layers helps teams understand whether failures stem from server capacity, upstream dependencies, or broader Internet connectivity problems.
Business Insider
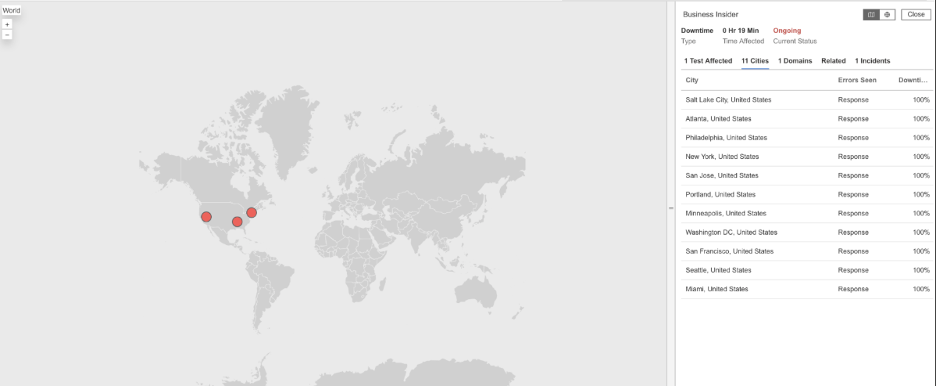
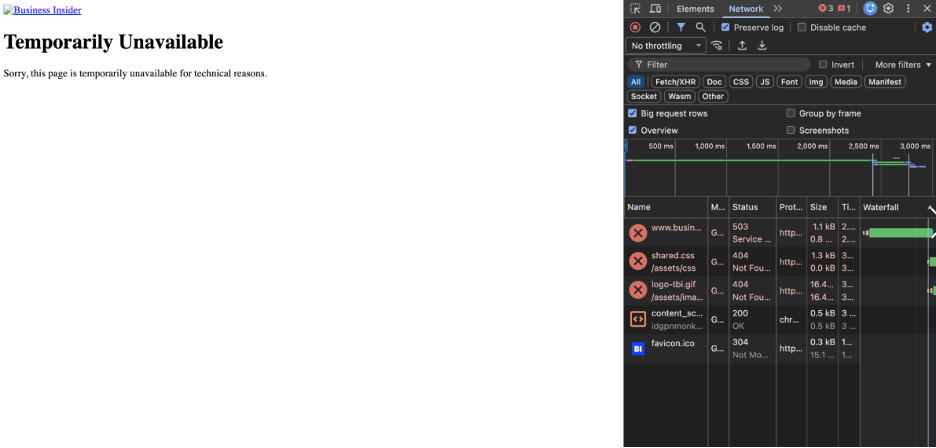
What Happened?
At 2:20 AM EST, Business Insider experienced a service disruption affecting users in North America. Users attempting to load articles were met with HTTP 503 (Service Unavailable) errors, which means the website’s servers were temporarily unable to handle requests. As a result, pages failed to load and the service was unavailable during the outage window.
Takeaways
Because Business Insider’s servers could not respond to requests, readers were unable to access news content when they needed it. For media and publishing sites, availability is critical, especially during breaking news cycles. External monitoring from multiple locations helps confirm when outages are affecting real users, while visibility into the application and delivery layers helps teams determine whether failures are caused by server capacity issues, backend dependencies, or broader connectivity problems.
Square
What Happened?
At around 1:33 AM EST, Square experienced a service disruption affecting users across several European countries. Users attempting to access Square services encountered HTTP 503 (Service Unavailable) errors, which means Square’s servers were temporarily unable to handle incoming requests. As a result, services were unavailable or unresponsive during the outage window.
Takeaways
Widespread HTTP 503 errors indicate that Square’s application layer was reachable but unable to serve requests, pointing to server-side capacity, internal failures, or upstream service dependencies rather than Internet reachability issues. For transaction-driven platforms, this underscores how failures within the application and dependency stack can immediately translate into user-visible downtime. From an SRE perspective, Internet Performance Monitoring (IPM) helps validate that the Internet path remains healthy while availability degrades, narrowing the blast radius to the service itself. Correlating regional error rates with latency and availability metrics helps teams confirm whether failures are caused by backend saturation, rollout issues, or cascading dependency failures, reducing time spent chasing non-relevant network or routing signals.
December
Traveltriangle
What Happened?
At around 7:00 PM EST, Traveltriangle experienced a service disruption affecting users in North America. Requests to the Traveltriangle website failed due to SSL certificate validation errors, caused by an expired SSL certificate. This means user browsers could not establish a secure HTTPS connection, resulting in blocked access and service unavailability during the outage window.
Takeaways
An expired SSL certificate is a single-point failure that can immediately render a service inaccessible, even when the underlying application and infrastructure are otherwise healthy. From an SRE perspective, this highlights the importance of monitoring TLS/SSL certificate validity as part of external availability checks, not just application uptime. Internet Performance Monitoring (IPM) helps confirm that failures occur during connection setup rather than deeper in the request lifecycle, allowing teams to quickly rule out application bugs or network path issues. Proactive certificate lifecycle monitoring and alerting are critical for preventing avoidable, user-visible outages caused by expiring security dependencies.
Google Search
What Happened?
At around 11:50 AM EDT, Google Search experienced degraded performance affecting users across North America. Requests to Google Search did not fail outright but showed elevated response times, driven largely by SSL/TLS delays during connection setup. This means secure connections were taking significantly longer than normal to establish, resulting in slow search responses during the outage window.
Takeaways
When SSL/TLS negotiation becomes slow, users experience degraded performance even though the service remains technically available. This type of issue sits between network reachability and application execution, making it easy to misclassify without detailed visibility. From an SRE perspective, Internet Performance Monitoring (IPM) helps break down where time is spent in the request lifecycle, distinguishing TLS handshake delays from server processing time. Monitoring SSL performance alongside overall availability allows teams to detect security-layer bottlenecks early and avoid prolonged “brownout” conditions where services are up but feel slow or unreliable to users.
Google Maps & Google Search
What Happened?
At around 7:11 AM EST, Google experienced service disruptions affecting multiple consumer services. In North America, users of Google Maps and Google Search encountered degraded performance and request failures. Requests failed with HTTP 502 (Bad Gateway) errors, which means one service received an invalid response from an upstream system it depends on. This pointed to instability within Google’s internal service chain rather than a full loss of Internet connectivity.
Takeaways
HTTP 502 errors surfacing across multiple Google services suggest a failure within a shared backend dependency or control plane, rather than isolated application bugs. Even at Google’s scale, tight coupling between internal services can expand the blast radius when a core dependency becomes unstable. This incident illustrates how multi-tenant backend components can create correlated failures across products that appear independent at the user level. Tracking error type, timing, and geographic scope together helps distinguish edge-level issues from deeper dependency failures, and reinforces the value of understanding how shared internal services affect externally visible reliability.
SAP CX AI
What Happened?
Between approximately 12:22 AM and 2:09 AM EST, SAP CX AI experienced a service disruption affecting users across multiple global regions. Requests to SAP CX AI services failed due to SSL/TLS errors, meaning secure connections could not be established successfully. The issue impacted multiple SAP CX AI service endpoints, resulting in widespread service unavailability during the outage window.
Takeaways
SSL/TLS failures can take down services instantly and globally, regardless of application health, because they occur before any request reaches the application layer. This incident highlights how certificate management and cryptographic dependencies represent high-impact, low-tolerance failure points in modern SaaS platforms. When multiple endpoints fail simultaneously due to SSL errors, it often indicates a shared certificate, trust chain, or configuration dependency, increasing blast radius across regions and services. Continuous validation of TLS handshakes and certificate expiry from outside the provider’s environment helps surface these issues early, before they block all user access and escalate into prolonged, global outages.
Azure West US 2
What Happened?
At around 2:49 PM EST, services hosted in the Azure West US 2 region experienced a disruption affecting users in North America. Requests to Azure-hosted applications began returning HTTP 503 (Service Unavailable) errors, which means the servers were temporarily unable to process requests. This indicated a regional service issue within Azure West US 2, resulting in reduced availability during the outage window.
Takeaways
Regional HTTP 503 errors highlight the risks of single-region dependency, even within highly resilient cloud platforms. When a cloud region experiences capacity pressure or internal service instability, workloads that are not actively distributed across regions can become unavailable despite the broader platform remaining healthy. This event underscores the importance of regional isolation strategies, such as multi-region deployments and failover testing, for applications with availability requirements. Observing failures confined to a single cloud region helps distinguish regional infrastructure issues from application bugs or Internet-wide problems, enabling faster scoping and response during cloud provider incidents.
Mashery
What Happened?
At around 4:40 PM EST, Mashery experienced a global service disruption affecting users across multiple regions. Requests to Mashery services began returning HTTP 503 (Service Unavailable) errors, meaning the servers were temporarily unable to handle incoming requests. Alongside these errors, request times increased sharply, with users experiencing long waits before failures occurred. This combination indicated degraded performance and reduced availability during the outage window.
Takeaways
For API management platforms, elevated latency followed by HTTP 503 errors often signals control-plane or gateway saturation, where traffic reaches the service but cannot be processed fast enough. The sharp rise in wait times shows how performance degradation can act as an early warning before full request failures become widespread. Because API gateways sit directly in the request path for many downstream services, instability at this layer can quickly cascade into customer-facing outages. Tracking latency distributions alongside error rates helps distinguish overload conditions from hard failures and provides earlier signals for mitigation before availability drops completely.

Azure West US 2
What Happened?
On December 11, 2025, at 17:18 EST, Internet Sonar detected an outage affecting Azure West US 2 across multiple regions, in North America. Requests to iw-west-us2.azurewebsites.net began returning HTTP 503 (Service Unavailable – the server is temporarily unable to handle requests), indicating a service disruption in the Azure West US 2.
Takeaways
Short bursts of HTTP 503 errors often reflect transient capacity pressure or internal service restarts rather than sustained regional failures. These events may only be visible externally for a narrow window but can still affect workloads that lack retries or traffic buffering. This incident highlights the importance of graceful degradation patterns, such as client-side retries with backoff and queue-based processing, to absorb brief platform-level disruptions. Even low-severity cloud incidents reinforce the need to design applications that tolerate momentary service unavailability without cascading user-facing failures.
Azure West US 2
What Happened?
On December 10, 2025, from 01:15:20 to 01:25:21 EST, Internet Sonar detected an outage affecting Azure West US 2 across multiple regions, including the US and Canada. Requests to iw-west-us2.azurewebsites.net began returning HTTP 503 (Service Unavailable – the server is temporarily unable to handle requests) , indicating a brief service disruption in the Azure West US 2.
Takeaways
A short, well-defined window of HTTP 503 errors suggests a temporary loss of service readiness rather than a hard failure, such as components failing health checks during recovery or traffic being routed to instances not yet ready to serve. These events often occur during internal remediation, scaling actions, or dependency restarts, and can surface externally even when recovery is already underway. For consumers of cloud platforms, this highlights the importance of readiness probes, retry behavior, and circuit-breaking, since brief periods of partial unavailability can still translate into user-visible errors if clients treat 503s as terminal failures.
Fastly
What Happened?
On December 8, 2025, at 23:21 EST, Internet Sonar detected an outage affecting Fastly in Latin America. Requests from multiple locations experienced high connect times and began returning HTTP 502 (Bad Gateway ) for several domains, including fastly.cedexis-test.com, forms.gle, cdn.evgnet.com, api.paypalworld.com, www.paypalobjects.com, and help.venmo.com, indicating Fastly-dependent services were impacted.
Takeaways
The combination of slow connection setup followed by HTTP 502 errors points to instability at the CDN edge or regional point-of-presence, rather than isolated application failures. When a CDN encounters issues in a specific geography, the impact can cascade quickly across many unrelated services that share the same delivery layer. This incident highlights how regional CDN degradation can amplify blast radius, even when origin services remain healthy elsewhere. Observing where latency increases before errors appear helps distinguish edge instability from origin failures and underscores the importance of regional visibility when relying on shared Internet delivery infrastructure.
Mashery
What Happened?
On December 4, 2025, at 23:10:14 EST, Internet Sonar detected an outage affecting Mashery across multiple regions, Requests to secure.mashery.com and support.mashery.com began returning HTTP 503 (Service Unavailable – the server is temporarily unable to handle requests) indicating a service disruption impacting Mashery availability.
Takeaways
A near-simultaneous rise in HTTP 503 errors across regions suggests stress or failure in a shared control plane, rather than independent regional overloads. For globally distributed API platforms, this type of failure often points to centralized components such as authentication, configuration distribution, or traffic management becoming unavailable. The sharp increase in response times before failures indicates queue buildup and backpressure, where requests are accepted but stall before being rejected. This pattern reinforces the importance of monitoring latency distributions alongside error rates to identify early signs of systemic saturation before full global unavailability occurs.
Azure West US 2
What Happened?
On December 3, 2025, from 21:24:11 to 21:54:58 EST, Internet Sonar detected an outage affecting Azure West US 2 across multiple locations in North America, with requests to iw-west-us2.azurewebsites.net returning HTTP 503 (Service Unavailable – the server is temporarily unable to handle requests).
Takeaways
A sustained window of HTTP 503 errors followed by a clean recovery suggests a stabilization phase, where services gradually return to a healthy state after an internal fault rather than failing and recovering abruptly. These patterns are often associated with dependency warm-up, traffic rebalancing, or gradual restoration of service readiness across a region. Even when recovery is underway, users may continue to see failures until all components re-enter a healthy state. Measuring time-to-stability, not just time-to-first-success, is critical for understanding real user impact during cloud-region incidents and for validating whether recovery actions fully restored service health.
DeepSeek
What Happened?
On December 3, 2025, at 06:55 EST, Internet Sonar detected an outage affecting DeepSeek services across multiple countries, including the US, Canada, India, and Germany, with requests to https://platform.deepseek.com/ and https://www.deepseek.com/ experiencing high wait times and returning HTTP 504 (Gateway Timeout – the server did not receive a timely response from an upstream server).
Takeaways
HTTP 504 errors combined with rising wait times typically indicate upstream dependency saturation or responsiveness issues, rather than failures at the service edge. This pattern suggests that DeepSeek’s front-end remained reachable while downstream components—such as model inference backends, data services, or internal APIs—were unable to respond within expected time limits. For AI-driven platforms, where request processing can be compute-intensive, these timeouts highlight the risk of queue buildup and cascading latency under load. Monitoring request duration distributions alongside timeout errors helps distinguish capacity exhaustion from hard failures and provides early signals before dependency delays turn into widespread availability loss.
November
Stack Overflow
What Happened?
On November 30, 2025, at 15:55 EST, Internet Sonar detected an outage affecting Stack Overflow across multiple countries, with requests to https://stackoverflow.com and https://stackoverflow.com/users/login returning HTTP 503 (Service Unavailable – the server is temporarily unable to handle requests).
Takeaways
Simultaneous failures on the homepage and login path point to an issue in a shared application dependency, rather than a problem isolated to authentication or user sessions alone. When core services such as request routing, configuration, or internal APIs become unavailable, they can block both read-only and authenticated traffic at the same time. This incident highlights how foundational application components can become single points of failure even in otherwise modular architectures. Observing which user journeys fail together helps narrow root cause quickly and avoid misattributing issues solely to auth systems or user-specific services when the underlying failure is broader.
Cloudflare Public DNS 1.1.1.1
What Happened?
On November 26, 2025, at 00:28:20 EST, Internet Sonar detected an outage affecting Cloudflare Public DNS 1.1.1.1 across multiple regions, including the US, Canada, Chile, Germany, Italy, Netherlands, Peru, and Spain, timeout error for queries from Cloudflare Public DNS 1.1.1.1 resolver End users relying on Cloudflare’s 1.1.1.1 resolver may experience slowed or failed website and application lookups due to DNS queries timing out.
Takeaways
DNS timeouts are particularly disruptive because they prevent connections from starting at all, even when networks and applications are otherwise healthy. Unlike application-layer errors, DNS failures often manifest as broad, ambiguous connectivity problems across many unrelated services at once. This incident highlights how recursive resolvers act as a critical shared dependency, where localized resolver instability can cascade into widespread user-visible failures. Monitoring DNS query success rates and response times independently of application health is essential for quickly distinguishing name-resolution failures from routing, TLS, or server-side issues when large portions of the Internet appear unreachable at the same time.
Google Meet
What Happened?
On November 26, 2025, at 00:28:20 EST, Internet Sonar detected an outage affecting Google Meet across multiple regions, including Australia, India, Japan, Korea, Malaysia, Singapore, and Thailand, with requests to https://meet.google.com/ experiencing high wait times from multiple locations.
Takeaways
For real-time collaboration tools, latency is as impactful as outright failure. Even when services remain technically available, delays in connection setup or signaling can disrupt meetings, audio, and video quality. This incident illustrates how regional performance degradation can disproportionately affect interactive applications compared to traditional web workloads. Monitoring latency distributions and connection setup times by region is critical for detecting these “brownout” conditions early, especially for real-time services where user tolerance for delay is extremely low and performance issues surface immediately as usability problems.
Granify
What Happened?
On November 18, 2025, at 19:12:42 EST, Internet Sonar detected an outage affecting Granify across multiple regions, including the US, UK, Canada, Australia, and many others, with requests to matching.granify.com returning HTTP 502 (Bad Gateway – the server received an invalid response from an upstream server) from multiple locations.
Takeaways
HTTP 502 errors appearing simultaneously across regions indicate a failure between service layers, where Granify’s front-facing systems remained reachable but could not successfully communicate with upstream dependencies. This pattern often points to instability in shared backend services, partner integrations, or origin systems rather than edge connectivity issues. Because these failures surface at the gateway boundary, they can affect all regions at once even if the underlying problem originates in a single dependency. Tracking where errors occur in the request chain helps distinguish upstream dependency failures from application bugs and highlights how tightly coupled integrations can amplify blast radius during global incidents.
Cloudflare
What Happened?
On November 18, 2025, at 06:30:40 EST, Internet Sonar detected an ongoing outage affecting Cloudflare globally, with multiple domains returning HTTP 500 (internal server error – the server encountered an unexpected condition preventing it from fulfilling the request).
Takeaways
HTTP 500 errors at global scale typically point to failures within a provider’s internal control plane or shared service logic, rather than connectivity, routing, or origin reachability problems. When a core internal component fails, edge locations may remain reachable but still be unable to serve traffic correctly. This incident highlights how control-plane instability can surface externally as widespread application errors, even when network paths and customer origins are healthy. Distinguishing 500-level errors from 502/503 responses is critical, as they signal fundamentally different failure modes and help teams avoid misattributing global platform issues to customer infrastructure or Internet routing problems.
Microsoft Office
What Happened?
On November 18, 2025, at 01:43:53 EST, Internet Sonar detected an outage affecting Microsoft Office across multiple regions, including the US, Canada, Japan, and China. Requests to www.office.com began returning HTTP 503 (service unavailable response code – server temporarily unable to handle requests) from multiple locations.
Takeaways
Simultaneous HTTP 503 errors across multiple regions suggest a failure or overload in a shared service layer rather than isolated regional incidents. For large SaaS platforms, this often points to dependencies such as authentication, configuration services, or internal APIs that gate access to many front-end workloads at once. Even when infrastructure remains online, loss of readiness in these shared components can block user access globally. This incident highlights how global capacity management and dependency health are critical to preventing broad availability drops, and why understanding which shared services sit on the critical path is essential for limiting blast radius during platform-wide events.
SAP C4C
What Happened?
On November 15, 2025, at 08:05:49 EST, Internet Sonar detected a global outage affecting SAP C4C across multiple regions. Requests to several crm.ondemand.com domains began returning HTTP 503 (service unavailable response code – server temporarily unable to handle requests) from multiple locations, preventing users from logging in to sap service.
Takeaways
Login failures caused by HTTP 503 errors often point to issues in authentication or session-establishment services, which act as hard gates to the rest of the application. Even when core CRM functionality may still be operational, loss of the login path effectively renders the platform unusable. This incident highlights how authentication services represent high-blast-radius dependencies in SaaS platforms, where a single failure can block all user access globally. Tracking availability separately for login flows versus post-login application paths helps distinguish authentication-layer outages from broader application failures and speeds up root cause isolation when users report being “locked out” rather than seeing functional errors.
Microsoft Office
What Happened?
On November 9, 2025, at 15:29:28 EST, Internet Sonar detected an outage affecting Microsoft Office across multiple regions, including the US, Canada, Sweden, Norway, Poland, the UK, and France. Requests to www.office.com began returning HTTP 503 (service unavailable response code – server temporarily unable to handle requests)
Takeaways
A sudden wave of HTTP 503 errors across geographies often reflects systems hitting readiness or admission limits, where traffic arrives successfully but cannot be safely accepted. In large productivity platforms, this can be triggered by demand spikes, backend throttling, or protective load-shedding mechanisms designed to prevent deeper failures. While these safeguards help preserve overall platform stability, they surface externally as user-facing downtime. This incident highlights the importance of understanding how and when services shed load, and how traffic patterns can push global platforms past readiness thresholds even when infrastructure remains online.
X Corp. (Twitter)
What Happened?
On November 6, 2025, at 01:56:11 EST, Internet Sonar detected an outage affecting X across multiple regions, including the US, France, UK, Germany, Singapore, Ireland, and Australia. Requests to X.com began returning HTTP 520 (a server error returned when the origin gives an unexpected or invalid response) from multiple locations.
Takeaways
HTTP 520 errors sit at the boundary between edge infrastructure and origin services, signaling failures that don’t cleanly map to standard application or server error codes. This type of error often appears when origin servers crash mid-response, return malformed data, or reset connections unexpectedly. Because the edge remains reachable, failures can surface globally and simultaneously, even if the underlying issue is confined to a subset of origin systems. This incident highlights how edge–origin contract violations can produce opaque errors that are difficult to diagnose without visibility into both sides of the delivery path, and why tracking error semantics is critical for distinguishing protocol-level failures from pure application or capacity issues.
October
Cloudflare Public DNS
What Happened?
On October 31, 2025, at 03:54 PDT, Internet Sonar detected an ongoing outage affecting the Cloudflare Public DNS resolver (1.1.1.1). The issue is impacting multiple clients globally, and investigations show timeouts and server failures.
Takeaways
Server failures at the recursive resolver layer are especially disruptive because they block the very first step of Internet communication. Unlike latency spikes or partial application errors, DNS resolver failures cause broad, cross-service impact that can appear as “the Internet is down” to end users. This incident underscores how public recursive DNS services represent a shared, high-blast-radius dependency, where instability immediately affects many unrelated applications at once. Distinguishing between resolver timeouts and explicit server failures is important, as they point to different failure modes—overload versus internal resolver faults—and help narrow whether issues originate in capacity constraints, software defects, or upstream dependency breakdowns.
Azure

What Happened?
At approximately 11:41 AM EDT, Catchpoint’s Internet Sonar detected a widespread outage affecting Microsoft Azure services. The disruption caused elevated DNS and connection failures in Azure Front Door (AFD) availability tests across more than 200 cities worldwide. Users and applications relying on Azure experienced slow response times, failed DNS lookups, and connection timeouts when attempting to reach cloud-hosted resources.
Analysis from multiple vantage points indicated reachability incidents to Microsoft’s Autonomous System (AS), pointing to a control-plane or edge networking issue within Azure’s global infrastructure rather than a DNS resolution failure. The outage resulted in significant connectivity degradation for enterprise services, APIs, and web applications dependent on Azure’s cloud backbone.
Takeaways
This incident follows hot on the heels of AWS’s disruption, highlighting how fragile modern cloud ecosystems remain and how essential independent, global observability is for understanding and mitigating Internet-scale outages in real time.
Azure’s outage reinforces that even top-tier cloud providers are vulnerable to network-level disruptions. Continuous monitoring of the full Internet stack, spanning DNS, BGP routing, and application performance, is crucial for detecting and diagnosing failures beyond the provider’s own status updates. With independent, real-time visibility, organizations can identify whether connectivity issues stem from edge networks, control-plane errors, or global routing anomalies, reducing downtime and improving service resilience.
Compass Bank
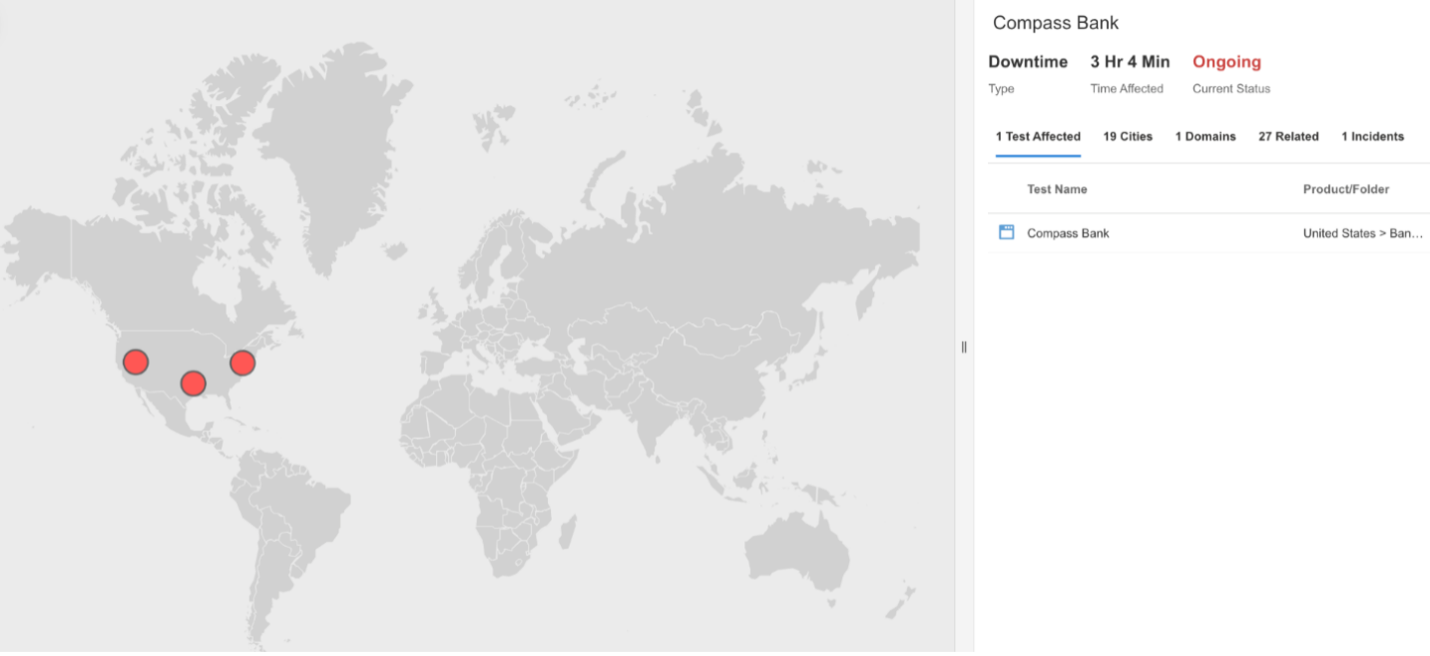
What Happened?
At approximately 1:28 PM EDT, Compass Bank experienced an outage that made its main website temporarily inaccessible. During the incident, users were unable to connect to the Compass Bank site due to connection failures, suggesting that the servers were unreachable because of network or infrastructure issues. The disruption prevented customers from accessing online banking features such as account management, bill payments, and transaction viewing until service was restored.
Takeaways
For financial institutions, even short outages can significantly impact customer trust and access to essential services. Monitoring both application availability and underlying network connectivity helps determine whether disruptions arise from local routing issues, server downtime, or data center outages. Continuous Internet stack visibility, from DNS to application endpoints, enables faster detection, clearer root cause identification, and improved service resilience for critical banking operations.
OpenStreetMap
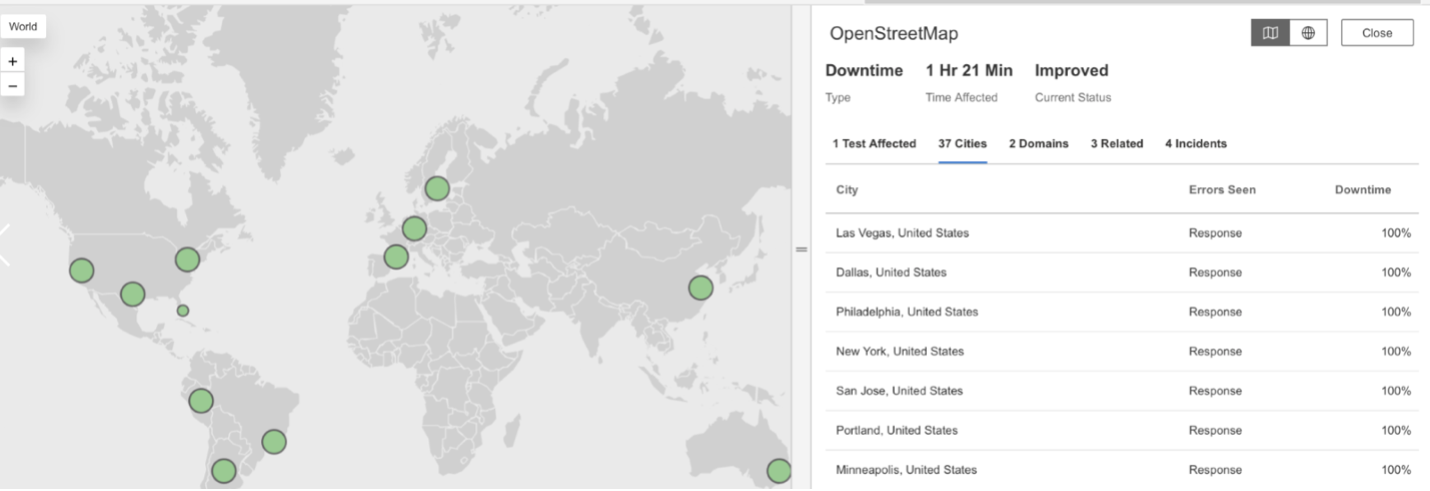
What Happened?
OpenStreetMap experienced two separate service disruptions—first on October 21, 2025, at 8:00 PM EDT, and again on October 23, 2025, at 4:09 PM EDT. During both incidents, requests to OpenStreetMap services returned HTTP 503 (Service Unavailable) responses, indicating that the servers were temporarily unable to process incoming traffic. Users likely encountered slow map loading times or were unable to access geographic data during the outages.
Takeaways
Repeated 503 errors over a short period can suggest server strain or resource exhaustion due to high user demand or maintenance activities. Continuous global monitoring helps determine whether such failures stem from traffic overload, capacity limits, or upstream infrastructure issues. For widely used mapping and open data platforms like OpenStreetMap, maintaining visibility into server health and request handling is essential to minimize downtime and preserve reliability for developers and users alike.
AWS
What Happened?
At approximately 06:55 AM UTC, Catchpoint’s Internet Sonar detected a large-scale outage impacting AWS infrastructure, 16 minutes before AWS officially updated its status page at 07:11 AM UTC. During the incident, multiple services hosted on AWS—including several Autodesk environments—returned HTTP 500 (Internal Server Error) and HTTP 502 (Bad Gateway) responses.
Takeaways
This outage highlights how even the most resilient cloud ecosystems can experience cascading failures. Independent global monitoring provided a 16-minute early detection window before AWS’s own acknowledgment, proving the importance of external visibility. By continuously observing the full Internet stack, teams can pinpoint whether service failures originate from infrastructure layers, network routes, or upstream dependencies, ensuring faster detection and mitigation during large-scale incidents.
SAP C4C
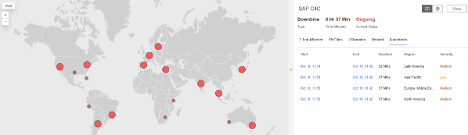
What Happened?
SAP C4C services experienced a medium-severity outage impacting users across multiple continents. During the incident, requests to the service returned HTTP 503 (Service Unavailable) responses, an error indicating that the servers were either overloaded or temporarily offline. The disruption likely affected access to CRM tools, sales management dashboards, and customer engagement applications that rely on SAP’s cloud infrastructure.
Takeaways
Service Unavailable errors across global regions suggest issues within centralized infrastructure or high service load. Continuous global monitoring can help distinguish between localized congestion and platform-wide server overloads. Tracking application health and response codes across distributed endpoints enables quicker identification of root causes and supports greater Internet and cloud service resilience.
AWS
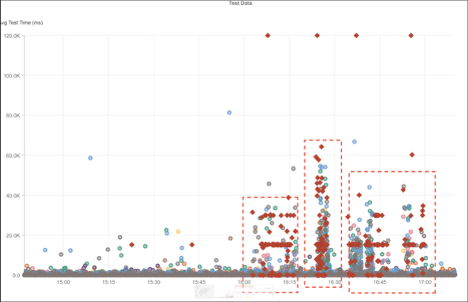
What Happened?
At approximately 4:02 PM EDT, AWS experienced an outage affecting the AP-Southeast-1 (Singapore) region, disrupting EC2 (Elastic Compute Cloud) services. The incident impacted multiple dependent platforms, including Kentik, Kasada, and Flowise. During the outage, affected systems returned a mix of HTTP 502 (Bad Gateway), HTTP 504 (Gateway Timeout), and HTTP 500 (Internal Server Error) responses—indicating failed communication between services, unresponsive servers, and internal processing errors. Users experienced connection failures and slow response times until normal service was restored.
Takeaways
This event illustrates how regional cloud outages can ripple across multiple dependent applications. Monitoring at both the cloud infrastructure and application layers helps distinguish whether disruptions stem from compute instance failures, overloaded gateways, or upstream service dependencies. Full Internet-stack visibility ensures faster diagnosis during multi-service incidents, improving resilience and minimizing downtime for platforms hosted on large-scale cloud providers like AWS.
Azure
What Happened?
At approximately 3:45 AM EDT, Microsoft Azure experienced an outage that affected access to multiple services across several regions. During the event, requests to Azure content delivery and edge network endpoints, such as azureedge.net and azurefd.net, failed to respond properly. The disruption likely impacted applications relying on Azure Front Door and CDN services, leading to slow loading times or unavailable web resources.
Takeaways
Outages at the edge layer highlight how failures in global content delivery or traffic routing can disrupt dependent cloud applications. Monitoring the full Internet delivery chain, from DNS resolution and CDN behavior to backend responses, helps pinpoint whether the issue lies in edge caching, upstream servers, or network routing. Maintaining end-to-end visibility into multi-region cloud infrastructure ensures quicker detection, accurate diagnosis, and faster recovery when outages occur.
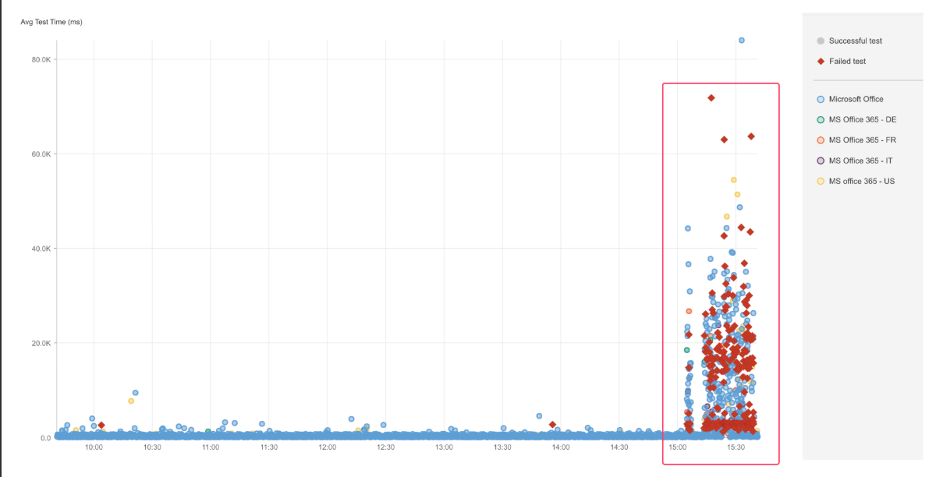
Microsoft Office

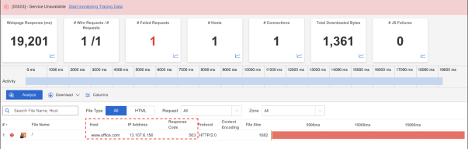
What Happened?
At approximately 5:21 PM EDT, Microsoft Office experienced a widespread outage affecting users across multiple continents. During the incident, requests to Office services returned HTTP 503 (Service Unavailable) responses, which occur when servers are too busy to handle new requests or are temporarily offline. The issue likely disrupted access to key productivity tools such as document editing, email, and cloud file storage.
Takeaways
Service Unavailable errors often indicate capacity or maintenance-related problems in large-scale distributed systems. Continuous global monitoring can help distinguish whether 503 responses stem from overloaded application servers, misconfigured load balancers, or temporary service throttling. Monitoring the full Internet delivery path—from the client through DNS and cloud infrastructure—provides essential insight into performance degradation and helps teams restore availability more quickly.
X Corp. (Twitter)

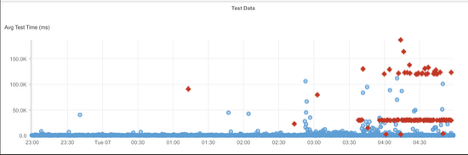
What Happened?
At approximately 4:10 AM EDT, X/Twitter experienced a brief service disruption impacting users across the EMEA region. During the outage, requests to the platform timed out due to high wait times and a lack of server responses. As a result, users encountered delays in loading feeds or were temporarily unable to access the site until normal operations resumed.
Takeaways
Timeout-related issues often point to network congestion or unresponsive backend servers. Monitoring end-to-end connection health, from DNS resolution through to application response, helps detect where latency builds up in the delivery chain. For global platforms like X, continuous visibility across multiple geographies ensures that localized disruptions can be quickly identified and isolated before they affect a broader user base.
Dropbox
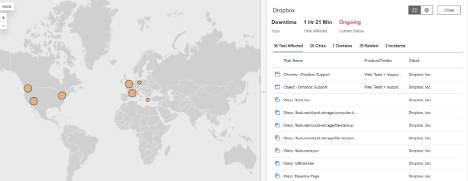
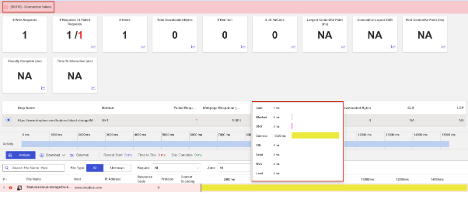
What Happened?
At approximately 2:45 AM EDT, Dropbox experienced a minor service disruption impacting users across multiple regions. During the incident, connections to Dropbox’s main service endpoint failed due to high connect times, meaning users’ devices took too long to establish a stable connection with Dropbox servers. The issue likely caused short delays or temporary inaccessibility for file uploads, downloads, and account access.
Takeaways
Even low-severity outages caused by elevated connection times can affect user experience, particularly for services handling large data transfers. Continuous monitoring of network latency and connection performance helps identify whether delays stem from local congestion, ISP routing, or upstream infrastructure issues. Having visibility across global endpoints ensures teams can detect and resolve small issues before they escalate into widespread disruptions.
Braintree
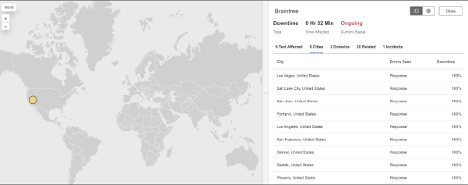
What Happened?
At around 8:00 PM EDT, Braintree experienced a service outage that affected payment processing operations across North America. During the incident, requests to Braintree’s web and API endpoints returned HTTP 503 (Service Unavailable) errors, indicating that the servers were either overloaded or temporarily taken offline for maintenance. This disruption likely prevented merchants from processing transactions or accessing their dashboards during the event.
Takeaways
Payment systems depend on continuous uptime to maintain customer trust and transaction flow. Monitoring both API availability and response times helps detect early signs of overloads or maintenance misconfigurations before they cause service-wide failures. Internet Performance Monitoring, spanning DNS, application servers, and network connectivity, can reveal where in the chain performance degrades, helping teams minimize downtime and protect critical financial operations.
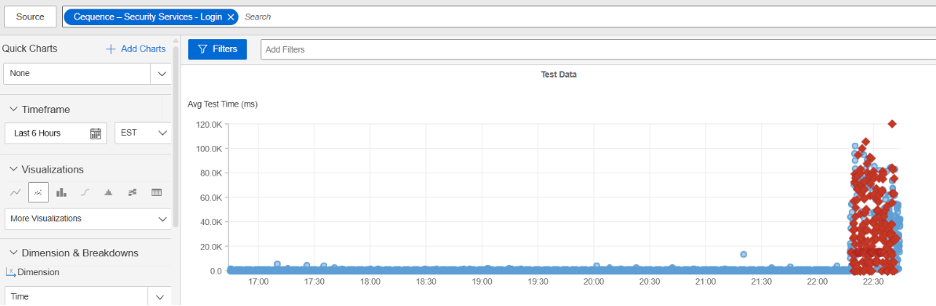
Cequence
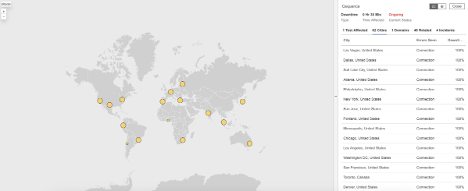
What Happened?
At approximately 11:20 PM EDT, Cequence experienced a global outage that affected user access across multiple continents. During the incident, requests to Cequence login services returned HTTP 504 (Gateway Timeout) errors—meaning that the gateway or proxy server did not receive a timely response from an upstream system. The issue was linked to high connection times, causing requests to fail. The disruption lasted about 30 minutes, and normal functionality resumed by 11:50 PM EDT.
Takeaways
Global outages like this highlight how latency and timeout issues in upstream systems can cascade across regions. Monitoring connection times and response behavior across the Internet stack, from client to application, helps identify where delays occur and which systems are most affected. Comprehensive visibility enables teams to distinguish between server-side slowness, network congestion, and external dependencies, improving overall service resilience.
Meetup
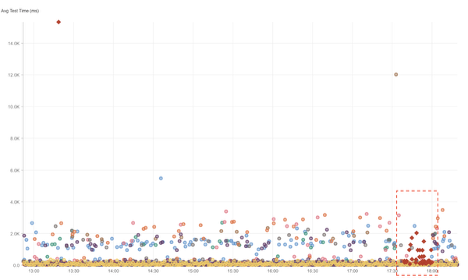
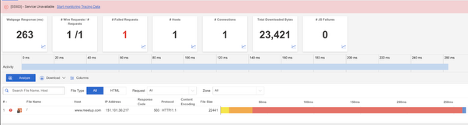
What Happened?
At around 5:39 PM EDT, Meetup experienced a major outage affecting users in the United States. During the incident, requests to the service returned HTTP 503 (Service Unavailable) errors, which occur when a server is temporarily unable to handle requests—often due to overload or maintenance. The disruption lasted roughly 20 minutes, with normal access restored by 5:59 PM EDT. Users were unable to view or manage events, RSVP, or log into their accounts during this period.
Takeaways
Short but high-impact outages like this demonstrate how quickly application-level failures can affect user trust and engagement. Synthetic monitoring across multiple locations can help confirm whether 503 errors stem from overloaded servers, failed backend dependencies, or temporary maintenance issues. Maintaining visibility into server health and response behavior supports faster remediation and stronger Internet resilience for community-driven platforms like Meetup.
LaunchDarkly
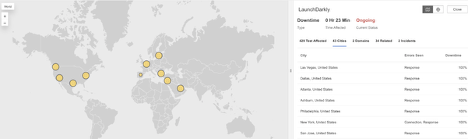
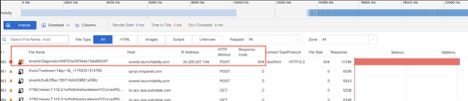
What Happened?
At approximately 10:55 AM EDT, LaunchDarkly experienced a multi-region outage that disrupted access to key services. Users encountered a mix of Connection Timeout, HTTP 502 (Bad Gateway), and HTTP 504 (Gateway Timeout) errors—indicating that the servers either failed to respond in time or returned invalid responses. This affected the platform’s ability to deliver real-time feature flag updates and event tracking, impacting software teams relying on LaunchDarkly for continuous deployment and feature control.
Takeaways
This outage highlights the importance of monitoring both application endpoints and their supporting network paths. When multiple error types appear simultaneously, it often points to issues between load balancers, upstream servers, or edge locations. End-to-end Internet visibility helps identify whether slow responses, timeouts, or upstream failures originate within the provider’s infrastructure or across the wider Internet, improving the speed of root cause analysis and recovery.
September
Cheapflightnow

What Happened?
At 7:34 AM EDT, Cheapflightnow’s website stopped working across parts of the U.S. Visitors saw HTTP 522 errors, which is a Cloudflare-specific error. This means Cloudflare was working fine, but it couldn’t connect to Cheapflightnow’s own servers — either they were down or too slow to respond.
Takeaways
Cloudflare’s global network stayed up, but because Cheapflightnow’s own servers weren’t answering, users still experienced outages. To prevent this, companies often set up backup origin servers (extra copies of their main servers) so if one fails, traffic can be rerouted to another. The outage also shows how dependencies between CDNs and origin servers can create weak links. By monitoring the full Internet stack, from DNS to CDN to application servers, companies can quickly see where the chain breaks and reduce downtime.
Alaska Airlines


What Happened?
At 10:27 PM EDT, Alaska Airlines’ main website www.alaskaair.com became unavailable across many major U.S. cities. People saw HTTP 503 Service Unavailable and HTTP 500 Internal Server Error messages. A 503 error means the server is too busy or down for maintenance, while a 500 error is a general “something went wrong” message inside the system.
Takeaways
When both 500 and 503 errors appear together, it often means the problem isn’t just a single overloaded server, but a deeper system-wide issue. For airlines, outages can delay flight bookings and check-ins, so implementing proactive Internet Performance Monitoring (IPM) and building strong backup systems is critical to keep operations running smoothly.
Microsoft Office

What Happened?
Between 1:10 PM and 1:51 PM EDT, the Microsoft Office website www.office.com stopped working in several countries. During the outage, requests returned HTTP 503 (Service Unavailable) responses.
Takeaways
This outage was likely caused by temporary server overload or a configuration mistake. The quick recovery suggests Microsoft’s backup systems kicked in and restored service. The issue here is that Microsoft Office is used by millions. Having proactive Internet Performance Monitoring (IPM) ensures even brief disruptions are detected, measured, and understood, helping IT teams validate resilience and improve user experience.
SAP C4C
What Happened?
At 11:08 AM EDT, people using SAP C4C (a cloud-based customer management tool) were unable to access services worldwide. Requests to ondemand.com showed HTTP 503 Service Unavailable errors, meaning the servers were not able to handle the traffic.
Takeaways
Because the outage struck so many regions at once, it likely stemmed from a central cloud infrastructure issue. Global SaaS services rely on load balancing to distribute traffic and keep performance stable. With synthetic monitoring across multiple geographies, businesses can confirm availability worldwide and ensure their customers are not locked out.
SAP Concur
What Happened?
From 3:39 PM to 3:51 PM EDT, SAP Concur — used for business travel and expense management — went down in multiple regions. Attempts to connect to www.concursolutions.com returned HTTP 503 Service Unavailable errors.
Takeaways
Even though this outage was brief, 503 errors meant the servers couldn’t handle requests. For enterprise apps like Concur, even minutes of downtime can disrupt financial operations. End-to-end monitoring, from DNS resolution to application response, helps companies verify reliability and spot weak points before they cause visible failures.
Aleph Alpha


What Happened?
At 4:20 AM EDT, Aleph Alpha’s website had problems in several countries. Users faced connection failures and very slow load times, meaning their browsers couldn’t establish a stable link to the servers.
Takeaways
Slow connections and failures can point to DNS issues, routing problems, or server overloads. For AI providers, these disruptions damage reliability. Monitoring DNS and BGP (the routing system of the Internet) can quickly pinpoint whether failures come from the network layer or the servers themselves, supporting faster fixes and better resilience.
Dynatrace

What Happened?
At 2:58 AM EDT, Dynatrace’s login service stopped working for users in multiple countries including the United Kingdom, Romania, Serbia, the Netherlands, and South Africa. People trying to sign in faced connection failures, meaning their devices couldn’t reach the login servers at all.
Takeaways
Because the login service failed, users couldn’t access Dynatrace even though the rest of the platform may have been running. This highlights a unique challenge: monitoring tools themselves depend on the same Internet stack they measure. Outages in DNS, routing (BGP), or authentication layers can ripple into monitoring platforms. Independent, external monitoring provides a safety net — essentially, “monitoring the monitors” — to ensure visibility doesn’t disappear when the tools themselves are impacted.
Google Mail
What Happened?
From 10:40 to 11:20 AM EDT, Gmail users couldn’t log in. Attempts to access the login page returned HTTP 502 Bad Gateway errors, which means one server received an invalid response from another. Users also saw slower load times beginning at 10:26 AM EDT.
Takeaways
Login failures are especially disruptive because they block access even when the mail servers are fine. By monitoring full user journeys, from login through inbox, with synthetic monitoring, companies can catch these issues early and strengthen Internet resilience.
NS1


What Happened?
Between 7:08 and 7:32 AM EDT, NS1’s DNS services failed in multiple regions. DNS timeouts (when the system that translates website names into IP addresses doesn’t respond in time) disrupted access to many customer websites, including Pinterest.
Takeaways
When DNS fails, websites become unreachable even if their servers are healthy. Because NS1 underpins many services, its outages ripple widely. Independent monitoring of DNS health and Internet routing (BGP) is key to detecting failures quickly and confirming their scope.
Booking.com
What Happened?
At 8:00 PM EDT, Booking.com services went down across multiple cities. Users received HTTP 502 Bad Gateway errors, meaning the servers handling traffic couldn’t reach the systems behind them.
Takeaways
For travel platforms, outages block reservations and damage trust. A 502 error often points to failures between load balancers and application servers. Synthetic monitoring of APIs and user transactions helps detect these failures early and show exactly where they occur in the service chain.
DemandBase

What Happened?
From 5:13 to 6:55 PM EDT, DemandBase experienced a global outage. Users faced HTTP 502 Bad Gateway errors, and later an SSL certificate error that blocked secure connections.
Takeaways
This outage combined server connection problems with a security misconfiguration. Since SSL certificates are required for encrypted access, an expired or invalid certificate can shut users out entirely. Monitoring of SSL health alongside DNS and application performance helps prevent small oversights from becoming major global failures.
Azure

What Happened?
At 3:33 PM EDT, Microsoft’s Azure cloud platform went down across multiple regions. Users saw HTTP 500 Internal Server Errors and HTTP 503 Service Unavailable responses. A 500 error means the server malfunctioned, while a 503 error means it was too busy or unavailable.
Takeaways
Azure is critical infrastructure for enterprises, so outages affect countless dependent services. Monitoring across the full Internet stack, from cloud infrastructure to DNS and CDNs, helps organizations understand whether the issue lies with the cloud provider or external
Microsoft Outlook

What Happened?
At 3:38 AM EDT, Outlook suffered an outage across North America. Users received HTTP 500 Internal Server Error responses, showing the problem was inside Microsoft’s servers.
Takeaways
Email is mission-critical for both business and government. Even short outages disrupt communication. Synthetic monitoring of SaaS services gives enterprises an independent way to detect disruptions early and confirm whether problems are with the provider or the Internet itself.

What Happened?
At 5:33 PM EDT, Twitter went down across multiple countries. Users saw HTTP 500 Internal Server Errors, meaning requests reached Twitter’s servers but failed due to internal issues.
Takeaways
Social media outages are highly visible. Internal server errors often stem from backend failures or overloads. Monitoring from global vantage points is critical to confirm whether an outage is regional or global, which helps providers respond faster.
Citibank
What Happened?
From 3:10 to 5:04 AM EDT, Citibank services were disrupted across North America. Customers faced HTTP 502 Bad Gateway errors, showing that front-end servers couldn’t reach the banking systems behind them.
Takeaways
For financial institutions, downtime blocks critical transactions and erodes trust. Monitoring across DNS, TLS, and application performance layers provides early warnings and helps ensure banking services remain resilient.
Alibaba Cloud

What Happened?
From 10:35 to 10:50 PM EDT, Alibaba Cloud experienced a regional outage. Users saw slow responses and a mix of errors: HTTP 500 Internal Server Error, 502 Bad Gateway, 504 Gateway Timeout, and 413 Payload Too Large.
Takeaways
The mix of errors shows stress across multiple parts of Alibaba Cloud’s infrastructure — from server overloads to request handling limits. With synthetic monitoring from distributed locations, businesses can confirm the scope of failures and reroute workloads to unaffected regions to maintain service availability.
August
Hotwire

What Happened?
On August 25, 2025, at 2:09 AM EDT, Internet Sonar detected an outage affecting Hotwire services across multiple regions, including the US and Canada. During the incident, requests to https://www.hotwire.com/ returned HTTP 504 (Gateway Timeout) and HTTP 503 (Service Unavailable) responses from multiple locations, starting at 2:09 AM EDT.
Takeaways
Service unavailability and gateway timeout errors can occur simultaneously, suggesting both server-side resource strain and upstream communication issues. The impact across multiple regions indicates that the outage was not localized, but rather a broader service disruption. Continuous monitoring with distributed vantage points was key to rapidly identifying the extent and nature of the failures.
Oppenheimer Funds

What Happened?
On August 23, 2025, at 7:35 AM EDT, Internet Sonar detected an outage affecting Oppenheimer Funds services across the North America region. During the incident, high connection time was observed for requests which belonged to the domain: https://www.oppenheimerfunds.com/
Takeaways
Unlike hard failures, latency-driven disruptions often lead to slower page loads, transaction delays, and potential session timeouts. Organizations should monitor not only for outright service failures but also for performance degradation, as these can signal early warnings of infrastructure stress or misconfigured dependencies. Proactive performance monitoring and capacity planning are critical for minimizing the business impact of such issues.
Netskope

What Happened?
On August 20, 2025, at 3:38 AM EDT, Internet Sonar detected an outage affecting Netskope across multiple regions of the United States. During the outage DNS resolution failures were observed for the domain https://www.netskope.com/, starting at 03:38:16 EDT from multiple US locations. Queries at Level 2 nameservers returned “unknown” responses due to 100% packet loss.
Takeaways
Even when application servers remain healthy, failures at the nameserver level can render services inaccessible to users. The 100% packet loss indicates a systemic issue rather than localized degradation, pointing to either a provider-side misconfiguration or a broader infrastructure disruption. To mitigate risks, organizations should consider implementing redundant DNS providers, monitoring resolution paths from diverse geographies, and preparing failover strategies that minimize user-facing impact when primary nameservers fail.
Spotify
What Happened?
On August 20, 2025, at 2:45 AM EDT, Internet Sonar detected an outage affecting Spotify services across multiple locations in the Asia Pacific region. During the incident, requests to clienttoken.spotify.com and apresolve.spotify.com returned HTTP 502 (Bad Gateway) and HTTP 504 (Gateway Timeout) responses.
Takeaways
This outage highlights the fragility of token authentication and service resolution endpoints, both of which are critical to ensuring seamless user access and playback functionality. Failures at these layers often prevent session validation and disrupt connectivity between client applications and core infrastructure. Organizations operating at global scale should implement robust redundancy for authentication and service discovery components, as well as proactive health checks to quickly detect and remediate gateway errors before they cascade into regional outages.
SAP C4C

What Happened?
On August 16, 2025, at 9:06 AM EDT, Internet Sonar detected an outage impacting SAP C4C services across multiple regions, including Asia Pacific, Europe, the Middle East and Africa, Latin America, and North America. During the incident, requests to https://my354302.crm.ondemand.com returned HTTP 503 Service Unavailable responses.
Takeaways
This widespread outage demonstrates how service-layer failures can propagate globally when centralized infrastructure experiences disruption. The uniform 503 errors suggest resource exhaustion or unavailability of backend systems rather than isolated network issues. For cloud-based CRM platforms supporting distributed enterprises, such incidents can severely hinder business continuity. To mitigate risk, providers should ensure adequate load balancing, geographic redundancy, and capacity safeguards to maintain availability across all served regions.
Datadog
What Happened?
On August 14, 2025, at 11:25 PM EDT, Internet Sonar detected an outage affecting Datadog services across multiple regions, including Europe, the Middle East, Africa, and North America. During the incident, requests to multiple Datadog domains, including app.datadoghq.com, logs.datadoghq.com, and synthetics.datadoghq.com, returned HTTP 503 Service Unavailable responses. The service disruption lasted approximately 5 minutes, with recovery observed by 11:30 PM EDT.
Takeaways
Although brief, this outage illustrates the operational impact of simultaneous failures across multiple critical service domains. For a platform like Datadog, which provides observability and monitoring at scale, even short-lived disruptions can have cascading effects on customers’ ability to track application health, detect incidents, and respond to ongoing issues. This event highlights the importance of service segmentation, robust failover mechanisms, and proactive incident communication to reduce the business impact of multi-domain availability failures.
It also raises the question of “who monitors the monitors?” Because Datadog is cloud-hosted, any disruption to its underlying hosting environment directly affects both its own services and customers’ visibility into their systems. This underlines the value of leveraging a robust monitoring strategy with multiple independent vantage points, ensuring continuity of insight even when a primary monitoring provider experiences downtime.
Netskope

What Happened?
On August 14, 2025, at 11:17 PM EDT, Internet Sonar identified an ongoing outage affecting Netskope services across multiple regions, including Asia Pacific, North America, Europe, the Middle East, and Africa. Requests to www.netskope.com have been returning HTTP 500 Internal Server Error responses from multiple global locations since the start of the incident, indicating a widespread server-side issue.
Takeaways
This incident demonstrates the risks posed by core server-side failures, where application infrastructure becomes unable to process requests globally. HTTP 500 errors typically point to misconfigurations, software bugs, or overloaded backend systems—issues that can quickly cascade across a cloud-delivered platform like Netskope. The simultaneous global impact underscores the importance of resilient deployment strategies, such as distributed service clusters, failover mechanisms, and staged rollouts to minimize widespread disruption.
For security and cloud access providers, outages of this nature can be particularly disruptive, as they impair the very services enterprises rely on for secure connectivity. Proactive monitoring across multiple regions is essential for rapid detection and faster root-cause isolation. Although brief, this outage illustrates the operational impact of simultaneous failures across multiple critical service domains.
TikTok


What Happened?
On August 14, 2025, at 4:36 PM EDT, Internet Sonar detected an outage impacting TikTok services in North America. During the incident, requests to https://www.tiktok.com/en/ began returning HTTP 504 Gateway Timeout responses. The outage lasted approximately 11 minutes, with services restored by 4:47 PM EDT.
Takeaways
This short-lived but disruptive outage highlights how gateway-level failures can quickly impact availability for a large user base. HTTP 504 errors often point to issues with upstream services or overloaded edge infrastructure, preventing requests from being properly routed or processed. For consumer-facing platforms like TikTok, even brief downtime can cause a noticeable user experience impact at scale. Ensuring redundancy at the gateway layer and deploying rapid failover mechanisms are critical steps for minimizing the effect of such time-sensitive disruptions.
Aurus Credit Processing

What Happened?
On August 14, 2025, at 1:23 AM EDT, Internet Sonar detected an outage affecting Aurus Credit Processing services across multiple regions, including Asia Pacific and North America. During the outage, requests to www.aurusinc.com experienced connection failures and elevated connect times. The disruption was short-lived, with services recovering by 1:30 AM EDT.
Takeaways
Even brief outages in payment and credit processing services can have outsized consequences, disrupting transaction flows and undermining customer trust. In this case, elevated connection times paired with outright failures suggest transient network or infrastructure strain rather than a full service breakdown. Such incidents highlight the importance of monitoring latency as closely as outright availability, since early performance degradation often precedes broader outages. Implementing redundancy in payment gateways and ensuring rapid failover mechanisms are key to minimizing disruption in mission-critical financial services.
ING Bank (Voya)

What Happened?
On August 13, 2025, at 1:05 PM EDT, Internet Sonar detected an outage impacting ING Bank (Voya) services. During this period, requests to https://www.ing.com returned HTTP 504 Gateway Timeout responses. The outage was observed for approximately one hour, with normal functionality restored by 2:05 PM EDT.
Takeaways
A one-hour outage for a major financial institution highlights the critical nature of maintaining consistent online availability in the banking sector. Gateway timeout errors typically indicate issues with upstream servers or overloaded infrastructure, suggesting that backend systems were unable to respond to client requests during the disruption. For customers, the inability to access digital banking services for an extended period can erode trust and disrupt critical financial activities.
This incident underscores the need for robust redundancy, proactive traffic management, and continuous monitoring to quickly identify and remediate infrastructure bottlenecks. Financial institutions, in particular, benefit from layered failover mechanisms that can mitigate the impact of gateway-level failures and minimize customer-facing downtime.
Azure Central India
What Happened?
On August 11, 2025, at 2:38 PM EDT, Internet Sonar detected an outage impacting Azure Central India services, specifically affecting GitHub availability. During the incident, requests to https://github.com began returning HTTP 503 Service Unavailable responses. The outage was observed across the Asia pacific region and lasted approximately 14 minutes, with outage recovering by 2:52 PM EDT
Fredericks

What Happened?
On August 7, 2025, at 4:34 PM CDT, Internet Sonar detected an outage impacting Fredericks services. The issue was observed across multiple cities in the United States. Requests to the website, https://www.fredericks.com, began returning HTTP 500 Internal Server Error responses, indicating a server-side failure.
Takeaways
HTTP 500 errors point to underlying server or application issues rather than network-level disruptions, suggesting that Fredericks’ backend systems were unable to handle incoming traffic during the outage. For retail and e-commerce platforms, such failures can directly affect revenue and customer trust, particularly if they occur during peak traffic periods. This event underscores the importance of robust application monitoring, load testing, and redundancy in backend infrastructure to minimize downtime caused by server-side instability.
Optimizely

What Happened?
On August 5, 2025, at 4:24 AM EDT, Internet Sonar detected a global outage affecting Optimizely services. The incident impacted users across multiple regions, including Asia Pacific, Americas, Europe, Middle East, and Africa. Requests to the primary domain, www.optimizely.com, began returning HTTP 502 Bad Gateway errors, accompanied by high wait times. These issues were consistently observed from several global locations, indicating a widespread disruption in service availability.
Takeaways
This outage illustrates how upstream service failures can escalate into global availability problems, with bad gateway errors signaling breakdowns in communication between edge servers and core application infrastructure. The concurrent observation of high wait times suggests that backend systems were not only failing but also struggling to respond under load. For digital experience platforms like Optimizely, which customers depend on for real-time content delivery and experimentation, even short-lived disruptions can interrupt critical business operations worldwide.
To mitigate risks of this scale, organizations should implement multi-region redundancy, strengthen gateway failover mechanisms, and proactively test performance under load to identify bottlenecks before they result in systemic outages.
ServiceNow
.avif)
What Happened?
On August 4, 2025, between 7:35 AM and 8:00 AM EDT, Internet Sonar detected an outage affecting ServiceNow services across multiple regions. The disruption was linked to high load conditions, which led to increased connection times and widespread connection failures for requests directed at ServiceNow.
Takeaways
Short-lived but multi-region outages caused by high load can have outsized effects, especially for enterprise platforms like ServiceNow that underpin critical workflows. Even a 25-minute disruption can cascade into missed service tickets, delayed automations, and user frustration. This incident highlights the importance of proactive capacity planning, load balancing across regions, and early detection of rising connect times—not just outright failures. Monitoring for these early warning signs enables faster intervention before performance degradation escalates into visible outages
PayPal
.avif)
What Happened?
On August 1, 2025, from 8:25 AM to 9:45 AM EDT, Internet Sonar detected a global outage impacting PayPal services across multiple regions. Beginning at 8:27 AM EDT, requests to the domains api.paypal.com and paypal.com returned HTTP 503 Service Unavailable errors from several locations, indicating widespread service disruption.
Takeaways
When a global payments platform like PayPal experiences 503 errors, even for a little over an hour, the impact can ripple across e-commerce, retail checkouts, and peer-to-peer transactions. For financial services, availability is as critical as security—every failed request represents lost revenue and customer trust. This outage underscores the need for redundant payment routes, automated failover strategies, and real-time monitoring that distinguishes between localized slowdowns and systemic backend failures. Proactive mitigation can keep essential transaction flows running, even during upstream service instability
July
Bluecore
.avif)
What Happened?
On July 22, 2025, at 11:25 PM EDT, Internet Sonar detected an outage affecting Bluecore services across multiple regions. The incident impacted users in the Asia Pacific, Europe, Middle East and Africa, and America. Requests to the domain www.bluecore.com returned HTTP 500 Internal Server Error responses from several locations, indicating a server-side failure and resulting in service disruption.
Takeaways
HTTP 500 errors point to underlying server-side issues that can quickly ripple across regions when left unmitigated. For platforms like Bluecore, which power customer engagement and marketing operations, even short outages can delay campaigns and reduce user trust. This incident highlights the importance of resilient backend architectures, failover-ready application tiers, and proactive monitoring that can spot and isolate server-side breakdowns before they cascade globally. Fast detection and escalation are essential to minimize downtime and protect customer-facing operations.
Google Mail
.avif)
What Happened?
On July 18, 2025, from 10:58 AM to 12:01 PM EDT, Internet Sonar detected an outage impacting Google Mail in the US and Canada. Requests to accounts.google.com returned HTTP 503 Service Unavailable and 535 unofficial errors, accompanied by elevated wait times. The disruption caused widespread service instability, leaving users unable to reliably access Google Mail.
Takeaways
Mixed error codes like 503 and unofficial 535s, combined with long connection times, suggest backend strain that outpaced available capacity. For productivity-critical platforms like Google Mail, even a little over an hour of downtime can stall business operations and personal communications. This incident reinforces the need for granular monitoring of both error diversity and latency trends. Proactive throttling, load balancing, and regional failover strategies are key to preventing high-volume demand spikes from cascading into widespread mail disruptions.
iCloud
.avif)
What Happened?
On July 16, 2025, from 04:52 AM to 06:21 AM EDT, Internet Sonar detected a regional outage affecting iCloud services. The incident impacted users in Colombia, France, and Italy. Requests to the domain www.icloud.com returned HTTP 504 Gateway Timeout and 503 Service Unavailable errors during this period, indicating service instability.
Takeaways
A mix of 504 Gateway Timeout and 503 Service Unavailable errors points to backend overload compounded by upstream connectivity issues. For cloud storage and synchronization platforms like iCloud, regional outages can leave users locked out of files, backups, and device sync operations—critical daily workflows. This incident highlights the importance of regional redundancy, proactive capacity safeguards, and automated failover to keep essential services resilient. Continuous monitoring for timeout trends, not just outright failures, can help detect early warning signs before full service loss.
Optimizely
.avif)
What Happened?
On July 15, 2025, at 7:20 PM EDT, Internet Sonar detected a global outage affecting Optimizely services. The incident impacted users across Asia Pacific, Europe, Middle East and Africa, and the Americas. Requests to the primary domain, www.optimizely.com, returned a mix of error responses, including HTTP 502 Bad Gateway, 503 Service Unavailable, and unofficial status codes such as 524, 525, and 535. High wait times were also observed from multiple global locations. Manual access attempts confirmed the application was inaccessible during the outage, indicating service disruption
Cloudflare DNS Resolver
What Happened?
On July 15, 2025, starting at 5:50 PM EDT, Cloudflare’s 1.1.1.1 DNS resolver experienced a global outage lasting around 30 minutes. A misconfiguration in Cloudflare’s internal systems linked the resolver’s IP prefixes to a non-production service topology. When a new test location was added, it unintentionally triggered a global withdrawal of those prefixes from Cloudflare’s data centers—disrupting DNS resolution worldwide. A BGP hijack, detected around the same time, was not the cause but a separate latent issue surfaced by the route withdrawals. Service was restored after Cloudflare deployed a fix.
Citibank
What Happened?
On July 2, 2025, from 1:05 AM to 01:30 AM EDT, Catchpoint’s Internet Sonar detected a short but complete outage affecting Citibank services in the United States. Requests to www.citi.com returned consistent HTTP 502 Bad Gateway responses across at least nine cities, including New York, Los Angeles, Salt Lake City, and Washington D.C. The 25-minute disruption resulted in full downtime across all monitored locations, indicating a likely configuration or gateway-level failure that was quickly mitigated.
Takeaways
Short-lived but high-visibility outages like this can still erode user confidence. A 25-minute incident may sound brief, but for a banking platform, every minute of downtime can trigger customer complaints or failed transactions. This case highlights the importance of real-time alerting, fast root cause identification, and clear post-incident communication to maintain trust during service disruptions.
June
PayPal
What Happened?
On Jun 24, 2025, 0:02 AM EDT to Jun 24, 2025, 0:21 AM EDT, Internet Sonar detected an outage affecting PayPal services across multiple regions in North America. Requests to www.paypal.com showed unusually high wait times, indicating degraded performance and potential delays in service, application processing, or page loads.
Takeaways
Degraded performance—rather than a full outage—can be harder to detect and more frustrating for users. Elevated wait times without total failure suggest capacity bottlenecks or backend queuing issues. Monitoring for slowdowns is just as important as watching for outright errors, especially for high-volume platforms handling financial transactions.
Ometria
What Happened?
On June 13, 2025, at 2:49 AM EDT, Catchpoint’s Internet Sonar detected an extended outage affecting Ometria services. The disruption impacted 74 cities across the Americas, Europe, the Middle East, Africa, and Asia Pacific. Requests to ometria.com returned HTTP 500 (Internal Server Error) and 502 (Bad Gateway) responses, while cdn.ometria.com showed persistent connection failures—pointing to issues at both the origin and edge layers. The incident lasted nearly five hours, with widespread service disruption observed across both core domains.
Takeaways
500 and 502 errors across multiple regions point to backend or upstream provider issues, not just surface-level downtime. This incident shows why monitoring should flag sudden spikes in error types—not just outages—to catch partial failures early. Because the disruption spanned the US, Europe, and Asia, it also reinforces the need for globally distributed observability to capture the full scope of impact.
Google Cloud Platform
What Happened?
An automated quota update in Google Cloud’s global API-management system overwhelmed a policy database and triggered waves of 503 errors across more than 30 GCP services. The failure rippled outward, disrupting platforms such as Discord, Spotify, Snapchat, Twitch and Cloudflare. Most regions recovered within hours, while us-central1 remained degraded well into the afternoon.
Takeaways
Even the largest cloud providers aren’t immune—what started as a routine configuration update led to a global outage, proving that no platform is too big to fail. Status pages were nearly an hour behind, highlighting the need for independent, real-time monitoring from the edge. To stay resilient, teams should isolate failure domains and build multi-region or multi-provider failovers that keep critical user journeys running, even when a single hidden dependency breaks.
Bread Financial
What Happened?
On June 10, 2025, at 12:15 AM EDT, Bread Financial experienced a global outage. HTTP 503 errors and “no healthy upstream” responses indicating that servers were temporarily unavailable errors were observed on login requests to the domains member- portal.breadpayments.com and merchants.platform.breadpayments.com.
OpenStreetMap


What Happened?
On June 6, 2025, at 4:11 AM EDT, Internet Sonar detected an outage affecting OpenStreetMap services across multiple regions, including Asia Pacific, Europe, the Middle East and Africa (EMEA), and North America. Analysis revealed consistent HTTP 503 Service Unavailable responses for requests to www.openstreetmap.org, backend. The outage lasted approximately 35 minutes, with failures returning 503 errors throughout the duration of the incident.
Takeaways
Regional CDN or caching layer failures can expose unexpected pressure points in global availability, especially for open-data platforms with distributed infrastructure. This outage shows why it’s worth stress-testing how traffic is routed and served when backend services temporarily falter—particularly for projects without dedicated enterprise support teams.
Tiktok

What Happened?
On June 2, 2025, at 10:53 PM EDT, Internet Sonar detected an outage affecting TikTok services in the North American region. Analysis revealed HTTP 504 Gateway Timeout responses for requests to www.tiktok.com. During the incident, users reported being unable to access TikTok services, indicating significant service disruption.
Takeaways
Regional dependencies can introduce unexpected single points of failure. This incident highlights the importance of validating upstream provider reliability and implementing targeted failover strategies for region-specific disruptions. Proactively test how your service degrades under partial regional outages to ensure graceful handling and clear user communication.
May
OpenAI API

What Happened?
In the early hours of May 31, Catchpoint detected API timeouts and degraded performance for OpenAI’s API endpoint. The issue began in a few U.S. cities and quickly expanded to other locations. Catchpoint alerted the customer impacted by this incident, a global leader in consumer technology, over 40 minutes before OpenAI confirmed the issue. Failures included erratic responses and elevated latency.
Takeaways
Early, independent detection of third-party API issues enables teams to respond proactively—rerouting traffic, adjusting user messaging, or throttling non-critical features—before vendor confirmation. Relying solely on provider communications can delay mitigation and amplify user impact, especially when real-time experiences depend on external APIs.
Sallie Mae
What Happened?
On May 26, 2025, at 9:21 PM EDT, Internet Sonar detected an outage affecting Sallie Mae services across multiple North American regions. The disruption was caused by DNS failures for requests to www.salliemae.com, starting from 9:21 PM EDT and observed from multiple US locations. This DNS issue prevented requests from reaching the website, resulting in service inaccessibility.
Takeaways
DNS failures can instantly sever user access, regardless of backend health. To reduce detection and resolution time, implement DNS health checks from diverse external vantage points and integrate DNS incident response into runbooks. Regularly review DNS provider redundancy and failover strategies to prevent single points of failure at the network edge.
Google Bard

What Happened?
On May 26, 2025, at 8:45 AM EDT, Internet Sonar detected an outage affecting Google Gemini across multiple regions, including the US, EMEA, and APAC. The incident caused HTTP 502 Bad Gateway responses for requests to https://gemini.google.com/ from various locations. Users encountered error messages indicating that the server encountered an issue and could not complete their requests, resulting in service instability.
Takeaways
Widespread 502 errors signal upstream or gateway instability that can rapidly impact global availability. Distributed monitoring helps surface intermittent backend failures early, but actionable response depends on correlating error patterns across regions and isolating root causes. Regularly simulate backend failure scenarios and validate that fallback mechanisms and user-facing error handling minimize disruption during partial or cascading outages.
Hawaiian Airlines


What Happened?
On May 22, 2025, at 4:12 PM EDT, Internet Sonar detected an outage affecting Hawaiian Airlines services across multiple cities in the United States. Analysis showed consistent HTTP 503 Service Unavailable responses for requests to https://www.hawaiianairlines.com, indicating service unavailability and service disruption.
Takeaways
HTTP 503 errors often signal backend overload or service misconfiguration, and even brief global outages can cascade into significant operational and reputational impact for airlines. To minimize disruption, implement automated capacity safeguards, real-time health checks, and clear user-facing status messaging. Regularly test incident response plans to ensure rapid recovery and transparent communication during sudden, large-scale service interruptions.
OpenAI API ChatGPT

What Happened?
On May 22, 2025, at 5:20 AM EDT, OpenAI’s API (ChatGPT) experienced a global outage impacting APAC, EMEA, Latin America, and North American regions. Internet Sonar detected the disruption as requests to https://api.openai.com/v1/models began returning HTTP 5xx errors including 503, 504, and 500 suggesting server-side errors.
Takeaways
Simultaneous 5xx errors across multiple regions indicate systemic backend failures, not isolated network issues. Rapid triage requires distinguishing between error types (e.g., 500 vs. 503 vs. 504) to guide targeted mitigation. Ensure incident response playbooks include classification of error patterns and escalation paths for global third-party dependencies, enabling faster root cause analysis and more effective user communication.
Microsoft Office

What Happened?
On May 19, 2025, at 4:42 PM EDT, Microsoft Office experienced a global outage affecting access to its online services. Requests to https://www.office.com returned HTTP 503 Service Unavailable responses, indicating backend service unavailability. The disruption impacted service worldwide, preventing access to productivity tools related to Microsoft’s online services.
Takeaways
A global 503 outage for Microsoft Office underscores the risk of backend service dependencies at cloud scale. To reduce user impact, design for failover paths and cached access to critical productivity features during backend disruptions. Regularly test business continuity plans to ensure essential workflows remain accessible when core services are unavailable.
PayPal
What Happened?
On May 19, 2025, at 7:45 PM EDT, Internet Sonar detected a global service outage impacting PayPal across multiple regions. The disruption led to test failures, with significantly increased wait times observed for online and retail checkouts, indicating degraded service availability and performance.
Takeaways
Prolonged latency and degraded availability at scale can disrupt critical financial transactions and erode user trust. Prioritize real-time performance monitoring with automated alerting for high-traffic endpoints, and establish escalation protocols for rapid mitigation. Regularly stress-test payment workflows to identify bottlenecks and validate fallback procedures during widespread slowdowns.
SAP

What Happened?
On May 17, 2025, at 1:08 PM EDT, Catchpoint Internet Sonar detected a global outage affecting SAP services. The disruption impacted availability and performance across multiple regions, with elevated error rates and HTTP 503 responses observed. The outage affected domains under the crm.ondemand.com, indicating widespread service unavailability.
Takeaways
A surge in global 503 errors for SAP’s cloud CRM signals systemic backend or infrastructure issues that can paralyze business operations. Ensure robust alerting for critical SaaS dependencies and maintain clear runbooks for rapid escalation and customer communication. Regularly review service-level agreements and test continuity plans to prepare for large-scale SaaS disruptions.
Granify

What Happened?
On May 14, 2025, at 2:02 AM EDT, Catchpoint Internet Sonar observed failures in test runs affecting Granify services. The disruption resulted in HTTP 502 Bad Gateway errors, indicating upstream server issues. The outage impacted requests to the domain https://matching.granify.com/, with service instability observed in parts of South America.
Takeaways
Localized 502 errors point to upstream or intermediary failures that may go unnoticed without regional monitoring. Regularly audit edge infrastructure and upstream dependencies in less-trafficked regions to catch silent degradations early. Incorporate regional incident simulations to validate detection and response for geographically limited disruptions
Google cloud

What Happened?
On May 6, 2025, from 8:58 PM to 9:23 PM EDT, Internet Sonar detected an outage impacting Google Cloud services in Brazil. Analysis revealed HTTP 502 Bad Gateway errors and connection failures for requests resolving IPs associated with Google and Google Cloud, indicating temporary backend or network issues affecting service availability. The outage affected multiple services, including blue core, Apigee, Google Cloud, and Spotify.
Takeaways
A brief regional outage in a major cloud provider can disrupt multiple dependent services simultaneously. To minimize cascading impact, implement dependency mapping and automated failover for critical workloads in affected regions. Regularly review and test regional resilience strategies to ensure rapid recovery when cloud infrastructure experiences localized failures.
Optimizely

What Happened?
On May 6, 2025, at 10:16 PM EDT, Catchpoint Internet Sonar detected a global outage affecting Optimizely services. The disruption impacted availability and performance on the primary domain, https://www.optimizely.com, with elevated error rates and service interruptions observed across multiple regions.
Takeaways
Problems on the backend can quickly spread and cause issues in different regions, even if the Internet connection seems fine. It highlights the need for proactive monitoring to identify incidents that internal systems might miss, helping teams fix issues faster.
Bazaarvoice

What Happened?
On May 6, 2025, from 03:12 to 03:51 PDT, a global outage affected Bazaarvoice services, with the impact primarily seen in North America. The issue was identified through multiple Costco tests, which returned 502 Bad Gateway and 500 Internal Server Errors from the Bazaarvoice request endpoint: https://network-a.bazaarvoice.com/a.gif?.*. The outage was confirmed through the Internet Sonar Dashboard, showing its widespread impact.
April
Netskope

What Happened?
On April 25, 2025, from 00:41 to 01:04 EDT, Catchpoint’s Internet Sonar detected a global outage affecting Netskope. The incident impacted multiple regions, including APAC, EMEA, Latin America, and North America. The primary domain, https://www.netskope.com/, repeatedly returned HTTP 500 Internal Server Errors, indicating a server-side failure during this period.
Zendesk

What Happened?
On April 1, 2025, at 08:22 EDT, Catchpoint’s Internet Sonar detected a global outage impacting Zendesk services. The disruption resulted in widespread 500 Internal Server Errors across multiple systems. Zendesk confirmed the issue and announced an active investigation, though initial updates lacked details on the root cause, leading to uncertainty for affected users.
Takeaways
Early detection and communication are critical during service disruptions.
Clear, timely updates from service providers help reduce user confusion.
Proactive internal monitoring allows for faster user notification and operational adjustments during outages.
March
OpenAI

What Happened?
On March 30, 2025, at 06:01 EDT, Catchpoint’s Internet Sonar detected a global outage affecting the OpenAI API, specifically the endpoint https://api.openai.com/v1/models. The incident impacted users across APAC, EMEA, Latin America, and North America, with systems returning HTTP 500 Internal Server Error responses. The response indicated a backend processing issue, with OpenAI advising users to retry or contact support.
Takeaways
This outage highlights how widespread backend failures can instantly cascade across geographies. Even when connectivity is fine, server-side issues can halt functionality. That’s why teams must have external observability in place—to catch and isolate problems that internal telemetry might miss or delay.
Twitter/X

What Happened?
On March 28, 2025, between 2:50 PM and 3:10 PM EDT, Twitter experienced a partial global outage, with Catchpoint Internet Sonar detecting 503 Service Unavailable errors from multiple locations. Affected users were unable to access twitter.com, likely encountering a blank page or generic service failure response.
Takeaways
Short outages like this can still have major ripple effects, especially for high-traffic platforms. This incident highlights the need for real-time global monitoring and fast alerting to reduce MTTR. It also reminds teams to account for brief service degradations in their postmortems—users notice even short dips in availability.
Squarespace

What Happened?
On March 28, 2025, at 12:55 PM EDT, Catchpoint’s Internet Sonar detected a Squarespace outage affecting users in Europe, the Middle East, and Africa. The root cause was tied to 503 Service Unavailable errors and high connection times when accessing https://www.squarespace.com. Affected users saw website unavailability and potential delays in accessing Squarespace-hosted sites and services.
Takeaways
While regionalized issues can be harder to detect, this outage shows why it’s important to monitor from across the globe. The combination of slow connect times and 503s hints at server overload or infrastructure strain. For teams operating web-facing services, this underlines the value of Internet Performance Monitoring to identify partial or regional failures before customers start raising tickets.
British Airways

What Happened?
On March 27, 2025, at 22:45 EDT, Catchpoint’s Internet Sonar detected a service outage affecting the British Airways website (https://www.britishairways.com/). The disruption stemmed from too many redirects, likely triggered by a surge in user demand. Failures began as intermittent but quickly escalated to consistent outages across monitored tests.
Takeaways
Excessive redirects often signal underlying configuration or load-balancing issues—especially during high-traffic events. This highlights the importance of load testing under real-world conditions and having clear thresholds and fallback mechanisms in place. Continuous monitoring is key to catching issues before they snowball into full outages.
Criteo

What Happened?
On March 24, 2025, from 09:20 to 09:25 PST, an outage was observed on dynamic.criteo.com, impacting performance across Costco’s multiple domains. The issue caused significant increases in wait times, exceeding 10,000 ms, and led to a 71% dip in availability. Though short-lived at five minutes, the outage had a noticeable effect across 17 cities in North America.
Takeaways
Even minor outages can have outsized impacts when affecting high-traffic endpoints. Short disruptions can degrade user experience if they occur on critical service calls. Continuous monitoring is essential to detect and quantify these performance hits in real time.
Granify

What Happened?
Between 01:05 and 01:20 CDT on March 24, 2025, Granify experienced a service disruption impacting Footlocker. Tests showed request failures from six different locations. Although the outage lasted 15 minutes, the failures were localized and classified as low severity.
Takeaways
Localized outages, while not as visible as global incidents, can still disrupt user experience for specific regions or customers. Targeted monitoring helps identify these smaller-scale issues, ensuring affected partners are aware and can respond promptly.
Zendesk

What Happened?
On March 20, 2025, at 15:43 UTC, Zendesk experienced a global service outage due to 503 Service Unavailable and other 5xx server-side errors, impacting users’ ability to access support tools and communication channels. Catchpoint’s Internet Sonar detected the disruption 21 minutes before Zendesk acknowledged it, highlighting issues across multiple pods and regions. While core services were stabilized, intermittent failures continued for over 24 hours, delaying full recovery until March 21 at 22:59 UTC.
Takeaways
This outage showed how multi-pod infrastructure, while built for resilience, can complicate recovery when things go wrong. Early detection was key—internal teams took over 20 minutes to identify the root cause, during which businesses lost access to essential support workflows. The incident also highlights the need for independent, real-time monitoring to avoid delays, reduce downtime, and maintain trust. Understanding third-party dependencies isn’t optional—it's essential for modern SaaS operations.
Twitter/X

What Happened?
On March 10, 2025, starting at 5:30 AM EDT, users worldwide were abruptly disconnected from X. Over the next 24 hours, waves of outages—punctuated by brief recoveries—left users stranded, unable to access feeds, send messages, or engage with content.
The disruption spanned 30+ countries, from Argentina to the UAE, underscoring the platform’s global reliance.
Our own data collected over an extended baseline for X corp’s domains shows that during the outage there was a notable spike in the mean wait time. This suggests the servers were slower to respond—an effect that aligns with what typically occurs during a DDoS (Denial of Service) attack.
February
DocuSign

What Happened?
Between 5:50 and 6:09 EST, Catchpoint’s Internet Sonar detected an outage affecting DocuSign. Users in India experienced HTTP 502 Bad Gateway errors when attempting to access www.docusign.com. The issue led to complete downtime in cities such as Hyderabad, Ahmedabad, Bangalore, Delhi, and Chennai, with failures recorded across all monitored test locations.
Takeaways
This incident highlights how regional outages can significantly impact users, even if the issue is not global. Monitoring from geographically distributed locations is crucial for early detection and faster incident resolution.
January
Optimizely
What Happened?
Starting at 12:50 PM EST, Optimizely experienced a widespread latency issue affecting its Graph service. The outage impacted requests to cdn.optimizely.com and www.optimizely.com, with failures observed across multiple tests in different regions. Catchpoint’s Internet Sonar detected the issue early, confirming response timeouts and degraded performance across 68 cities. Optimizely later acknowledged the incident on its status page, stating that a fix had been deployed as of 17:41 UTC, though monitoring was ongoing.
2024
December
November
Microsoft Office 365


What Happened?
On November 25, 2024, Microsoft’s productivity tools, including Outlook, Teams, Exchange, and SharePoint, experienced a significant outage. The disruption began early Monday morning, leaving millions of users in affected European regions without access to critical communication and collaboration tools. The outage lasted over 24 hours. Many users reported patchy service, such as delayed emails and inaccessible attachments, while others were completely cut off.
Takeaways
This incident underscores the critical role of third-party monitoring in maintaining Internet resilience. Microsoft’s status page lacked timely updates, leaving users frustrated and uninformed. Proactive monitoring tools like Catchpoint’s Internet Sonar detected the outage early, highlighting service disruptions and confirming that the issue was isolated to Microsoft’s infrastructure. Early detection and real-time insights allowed businesses to mitigate the impact of the outage before Microsoft publicly acknowledged the problem.
October
Mashery
.avif)
What Happened?
On October 1, 2024, TIBCO Mashery, an enterprise API management platform leveraged by some of the world’s most recognizable brands, experienced a significant outage. At around 7:10 AM ET, users began encountering SSL connection errors. Internet Sonar revealed that the root cause wasn’t an SSL failure but a DNS misconfiguration affecting access to key services.
Takeaways
The Mashery outage reveals a crucial lesson: SSL errors can be just the tip of the iceberg. The real issue often lies deeper, like in this case, with a DNS misconfiguration. If DNS isn’t properly configured or monitored, the entire system can fail, and what seems like a simple SSL error can spiral into a much bigger problem. To truly safeguard against the fragility of the Internet, you need full visibility into every layer of the Internet Stack, from DNS to SSL and beyond.
September
Reliance Jio

What Happened?
On September 17, 2024, Reliance Jio encountered a major network outage affecting customers across multiple regions in India and across the globe. The outage was initially noticed when users began encountering connection timeouts attempting to access both the AJIO and Jio websites. The outage was resolved around 05:42 EDT.
Takeaways
Gaining full visibility across the entire Internet Stack, including external dependencies like CDN, DNS, and ISPs is critical for businesses. Proactive monitoring is essential for early detection of issues such as packet loss and latency, helping companies mitigate risks before they escalate into major outages.
August
ServiceNow
What Happened?
On August 15, at 14:15 PM ET, ServiceNow experienced a significant outage lasting 2 hours and 3 minutes. Catchpoint's Internet Sonar detected the disruption through elevated response and connection timeout errors across major geographic locations. The disruption, caused by instability in connectivity with upstream provider Zayo (AS 6461), impacted ServiceNow's core services and client integrations. The outage resulted in intermittent service availability, with users facing high connection times and frequent timeouts.
Takeaways
A proactive approach to BGP monitoring is crucial to prevent extended outages. ServiceNow's quick response to reroute traffic is a good example of how effective incident management and holding vendors accountable can make all the difference in keeping things running and keeping your users happy.
AWS

What Happened?
On August 14, between 8:00 and 8:25 UTC, AWS experienced a micro-outage affecting services like S3, EC2, CloudFront, and Lambda. Catchpoint's Internet Sonar detected connection timeouts across multiple regions, particularly in locations routing through CenturyLink AS209 and Lumen AS3356. This disruption, though not reflected on AWS’s status page, significantly impacted these regions' access to AWS services.
Takeaways
Status pages aren't always reliable indicators of service health. If you’re only relying on cloud-based monitoring tools, you’re in trouble if their cloud goes down. It’s good practice to diversify your monitoring strategy and have a fallback plan to ensure Internet resilience. Clear communication will also help you maintain trust with your users.
July
Disney+

What Happened?
On July 31, at 20:12 EDT, Disney Plus experienced a brief outage lasting 38 minutes. Catchpoint detected 502 Bad Gateway errors from multiple nodes, an issue that was confirmed through both automated tests and manual browsing. The disruption was resolved by 20:50 EDT.
Takeaways
This incident shows why it's so important to monitor your services from multiple vantage points to quickly detect and verify outages. Even short-lived disruptions can impact user experience, making continuous monitoring and rapid response essential.
Alaska Airlines

What Happened?
On July 23, from 14:35 to 14:52, Alaska Airlines’ website (www.alaskaair.com) experienced a 404 Not Found error, rendering the site inaccessible for approximately 20 minutes. Catchpoint detected the issue, confirming the failures across multiple tests. Response headers indicated the issue stemmed from configuration errors, as evidenced by the 404 error and subsequent cache miss responses.
Microsoft Outlook

What Happened?
Starting at 21:23 EDT on July 23, Microsoft Outlook experienced intermittent failures across multiple regions. Users encountered various errors, including 404 Not Found, 400 Bad Request, and 503 Service Unavailable, when trying to access https://www.outlook.com/ and https://outlook.live.com/owa/. Catchpoint’s Internet Sonar detected the issue through multiple tests, while Microsoft’s official status page did not report any outages at the time.
Takeaways
Another example of how intermittent issues, which can pose the most persistent threat to observability, may not be reflected on official status pages. Given the high cost of Internet disruptions, even a brief delay in addressing these issues can be extraordinarily expensive. And if you’re waiting for your provider to tell you when something’s wrong, that delay could be even longer.
Azure

What Happened?
On July 18, starting at 18:36 EDT, Azure’s US Central region experienced a major service outage lasting until 22:17 EDT. Initially, 502 Bad Gateway errors were reported, followed by 503 Service Unavailable errors. This outage impacted numerous businesses reliant on Azure Functions, as well as Microsoft 365 services like SharePoint Online, OneDrive, and Teams, which saw significant disruptions.
Takeaways
This incident occurred within 24 hours of a separate CrowdStrike outage, leading to confusion in the media as both issues were reported simultaneously. Companies that relied solely on Azure without multi-region or multi-cloud strategies were significantly impacted, particularly those using eCommerce APIs. Catchpoint’s Internet Sonar detected the outage early and helped isolate the issue, confirming that it wasn’t related to network problems, saving time on unnecessary troubleshooting.
CrowdStrike

What Happened?
On July 19, a massive global outage disrupted critical services worldwide, affecting systems dependent on Microsoft-based computers. The outage, caused by a faulty automatic software update from cybersecurity firm CrowdStrike, knocked Microsoft PCs and servers offline, forcing them into a recovery boot loop. This unprecedented outage impacted daily life on a global scale, grounding airlines, taking emergency services offline, and halting operations for major banks and enterprises.
Takeaways
The CrowdStrike outage is a wake-up call for how fragile our digital world really is. Everything we do relies on these systems, and when they fail, the ripple effects are huge. This incident shows just how important it is to be prepared. Know your dependencies, test updates like your business depends on it (because it does), and have a plan for when things go wrong. Don’t just assume everything will work—make sure it will. And remember, resilience isn’t just about your tech; it’s about your team too. Keep them trained, keep them ready, and make sure they know what to do when the unexpected happens.
June
May
Bing

What Happened?
On May 23, starting at 01:39 EDT, Bing experienced an outage with multiple 50X errors affecting users globally. The issue was detected by Catchpoint’s Internet Sonar and confirmed through manual checks. The outage disrupted access to Bing’s homepage, impacting user experience across various regions.
Takeaways
This incident shows the value of having robust monitoring in place. Quick detection and confirmation are crucial for minimizing the impact of such outages.

What Happened?
On May 1, starting at 10:40 Eastern, Google services experienced a 34-minute outage across multiple regions, with users encountering 502 Bad Gateway errors. The issue affected accessibility in locations including Australia, Canada, and the UK. Internet Sonar detected the incident and the outage was also confirmed via manual checks.
April

What Happened?
On April 29, starting at 03:29 EDT, X (formerly known as Twitter) experienced an outage where users encountered high wait times when trying to access the base URL 'twitter.com.' The issue was detected by Internet Sonar, with failures reported from multiple locations. Manual checks also confirmed the outage. Additionally, during this time, connection timeouts were observed for DFS and Walmart tests due to failed requests to Twitter’s analytics service, further impacting both platforms.
March
ChatGPT

What Happened?
On April 30, starting at 03:00 EST, ChatGPT’s APIs experienced intermittent failures due to HTTP 502 (Bad Gateway) and HTTP 503 (Service Unavailable) errors. Micro-outages were observed at various intervals, including 03:00-03:05 EST, 03:49-03:54 EST, and 03:58-03:59 EST. These disruptions were detected by Catchpoint’s Internet Sonar and confirmed through further investigation.
Takeaways
Even brief micro-outages can affect services and user experience. Early detection is key to minimizing impact.
February
ChatGPT


What Happened?
On February 25, 2024, at 23:29 EST, OpenAI’s ChatGPT API began experiencing intermittent failures. The primary issues were HTTP 502 Bad Gateway and HTTP 503 Service Unavailable errors when accessing the endpoint https://api.openai.com/v1/models. The outage was confirmed manually, and Catchpoint’s Internet Sonar dashboard identified the disruption across multiple regions, including North America, Latin America, Europe, the Middle East, Africa, and the Asia Pacific. The issues persisted into the next day, with 89 cities reporting errors during the outage.
Takeaways
As with many API-related outages, relying on real-time monitoring is essential to quickly mitigating user impact and ensuring service reliability across diverse geographies.
January
Microsoft Teams

What Happened?
On January 26, Microsoft Teams experienced a global service disruption affecting key functions like login, messaging, and calling. Initial reports indicated 503 Service Unavailable errors, with the issue captured by Autodesk synthetic tests. Microsoft later identified the root cause as networking issues impacting part of the Teams service. The failover process initially helped restore service for some regions, but the Americas continued to experience prolonged outages.
Takeaways
Failover processes can quickly resolve many service issues, but this outage showed the importance of ongoing optimization for full recovery across all regions. It also highlighted the value of monitoring from the user’s perspective. During the disruption, Teams appeared partially available, leading some users to believe the issue was on their end.
2023
December
Box

What Happened?
On December 15, from 6:00 AM to 9:11 AM Pacific Time, Box experienced a significant outage that affected key services, including the All Files tool, Box API, and user logins. The outage disrupted uploading and downloading features, leaving users unable to share files or access their accounts. Early detection through proactive Internet Performance Monitoring (IPM) helped Box mitigate the outage’s impact, with IPM triggering alerts as early as 04:37 AM PST, well before the outage became widespread.
Takeaways
Early detection and quick response are key to minimizing downtime, reducing financial losses, and protecting brand reputation. This incident emphasizes the value of a mature Internet Performance Monitoring strategy, setting the right thresholds to avoid false positives, and ensuring teams can quickly identify root causes to keep systems resilient.
Adobe

What Happened?
Starting at 8:00 AM EST on December 8 and lasting until 1:45 AM EST on December 9, Adobe’s Experience Cloud suffered a major outage, affecting multiple services like Data Collection, Data Processing, and Reporting Applications. The outage, which lasted nearly 18 hours, disrupted operations for Adobe’s extensive customer base, impacting businesses worldwide. Catchpoint's Internet Sonar was the first tool to detect the issue, identifying failures in Adobe Tag Manager and other services well before Adobe updated its status page.
Takeaways
Yet another reminder of the fragility of the Internet and another catch for Internet Sonar, which was essential for early detection and rapid response, helping to pinpoint the source of the problem and minimize downtime. The outage also highlights the importance of proactive monitoring and preparedness, as well as the potential financial and reputational costs of service disruptions.
November
October
September
Salesforce

What Happened?
On September 20, starting at 10:51 AM EST, Salesforce experienced a major service disruption affecting multiple services, including Commerce Cloud, MuleSoft, Tableau, Marketing Cloud, and others. The outage lasted over four hours, preventing a subset of Salesforce’s customers from logging in or accessing critical services. The root cause was a policy change meant to enhance security, which unintentionally blocked access to essential resources, causing system failures. Catchpoint detected the issue at 9:15 AM EST—nearly an hour and a half before Salesforce officially acknowledged the problem.
Takeaways
Catchpoint’s IPM helped identify the issue well before Salesforce's team detected it, potentially saving valuable time and minimizing disruption. For businesses heavily reliant on cloud services, having an IPM strategy that prioritizes real-time data and rapid root-cause identification is crucial to maintaining internet resilience and avoiding costly downtime.
August
July
June
Microsoft Teams

What Happened?
On 28 June 2023, the web version of Microsoft Teams (https://teams.microsoft.com) became inaccessible globally. Users encountered the message "Operation failed with unexpected error" when attempting to access Teams via any browser. Catchpoint detected the issue at 6:51 AM Eastern, with internal tests showing HTTP 500 response errors. The issue was confirmed manually, though no updates were available on Microsoft’s official status page at the time.
May
April
March
February
January
Microsoft

What Happened?
On January 25, 2023, at 07:08 UTC/02:08 EST, Microsoft experienced a global outage that disrupted multiple services, including Microsoft 365 (Teams, Outlook, SharePoint Online), Azure, and games like HALO. The outage lasted around five hours. The root cause was traced to a wide-area networking (WAN) routing change. A single router IP address update led to packet forwarding issues across Microsoft's entire WAN, causing widespread disruptions. Microsoft rolled back the change, but the incident caused significant impact globally, especially for users in regions where the outage occurred during working hours.
Takeaways
Catchpoint’s IPM helped identify the issue well before Salesforce's team detected it, potentially saving valuable time and minimizing disruption. For businesses heavily reliant on cloud services, having an IPM strategy that prioritizes real-time data and rapid root-cause identification is crucial to maintaining internet resilience and avoiding costly downtime.
2022
December
Amazon

What Happened?
Starting at 12:51 ET on December 5, 2022, Catchpoint detected intermittent failures related to Amazon’s Search function. The issue persisted for 22 hours until December 7, affecting around 20% of users worldwide on both desktop and mobile platforms. Impacted users were unable to search for products, receiving an error message. Catchpoint identified that the root cause was an HTTP 503 error returned by Amazon CloudFront, affecting search functionality during the outage.
Takeaways
Partial outages, even when affecting a small portion of users, can still have serious consequences. Relying solely on traditional monitoring methods like logs and traces can lead to delayed detection, especially with intermittent issues. Being able to pinpoint the specific layer of the Internet Stack responsible for the issue helps engineers troubleshoot and resolve problems faster.
November
October
September
August
July
Rogers Communications
What Happened?
On July 8, 2022, Rogers Communications experienced a major outage that impacted most of Canada for nearly two days, disrupting internet and mobile services. A code update error took down the core network at around 4 AM, affecting both wired and wireless services. The outage disrupted essential services, including 911 calls, businesses, government services, and payment systems like Interac. Some services were restored after 15 hours, but others remained down for up to four days. The incident impacted millions of Canadians, sparking widespread frustration and highlighting the risks of relying heavily on a single telecom provider.
Takeaways
Test thoroughly before deploying network changes and ensure redundancies are in place and effective. Rogers thought they had redundancies, but they failed to work when needed most. Fast detection and resolution are critical. Rogers' slow response led to significant financial losses, reputational damage, and a potential class-action lawsuit.
June
May
April
March
February
Slack

What Happened?
On February 22, 2022, at 9:09 AM ET, Slack began experiencing issues, primarily impacting users' ability to fetch conversations and messages. While users could log in, key functionalities were down, leading to widespread disruption. The issue persisted intermittently, affecting productivity for many businesses relying on Slack for communication. Catchpoint tests confirmed errors at the API level, pointing to issues with Slack’s backend services, not the network.
Takeaways
Early detection and real-time visibility into service performance is critical. Being able to quickly diagnose an issue and notify users before the flood of support tickets arrives can significantly reduce downtime and frustration. Monitoring from the user’s perspective is crucial, as it helps detect problems faster and more accurately than waiting for official service updates.
January
2021
December
Amazon Web Services (AWS)

What Happened?
In December 2021, AWS experienced three significant outages:
1. December 7, 2021: An extended outage originating in the US-EAST-1 region disrupted major services such as Amazon, Disney+, Alexa, and Venmo, as well as critical apps used by Amazon’s warehouse and delivery workers during the busy holiday season. The root cause was a network device impairment.
2. December 15, 2021: Lasting about an hour, this outage in the US-West-2 and US-West-1 regions impacted services like DoorDash, PlayStation Network, and Zoom. The issue was caused by network congestion between parts of the AWS Backbone and external Internet Service Providers (ISPs).
3. December 22, 2021: A power outage in the US-EAST-1 region caused brief disruptions for services such as Slack, Udemy, and Twilio. While the initial outage was short, some services experienced lingering effects for up to 17 hours.
Takeaways
Don’t depend on monitoring within the same environment. Many companies hosting their observability tools on AWS faced monitoring issues during the outages. It’s essential to have failover systems hosted outside the environment being monitored to ensure visibility during incidents.
November
Google Cloud

What Happened?
On November 16, 2021, Google Cloud suffered an outage beginning at 12:39 PM ET, which knocked several major websites offline, including Home Depot, Spotify, and Etsy. Users encountered a Google 404 error page. This outage affected a variety of Google Cloud services such as Google Cloud Networking, Cloud Functions, App Engine, and Firebase. Google’s root cause analysis pointed to a latent bug in a network configuration service, triggered during a routine leader election charge. While services were partially restored by 1:10 PM ET, the full recovery took almost two hours.
Takeaways
Monitor your services from outside your infrastructure to stay ahead of problems before customers notice. Tracking your service level agreements (SLAs) and mean time to recovery (MTTR) allows you to measure the efficiency of your teams and providers in resolving incidents.

